Adatkódoló táblázatok. Szöveges információk kódolása számítógépen
Amikor belépsz szöveges információk A karaktereket (betűket, számokat, jeleket) számítógépben kódolják különféle kódrendszerek segítségével, amelyek a szöveges információk kódolására szolgáló szabványok megfelelő oldalain elhelyezett kódtáblázatokból állnak. Az ilyen táblázatokban minden karakterhez egy meghatározott numerikus kód van hozzárendelve hexadecimális vagy decimális jelöléssel, azaz a kódtáblázatok a karakterképek és a numerikus kódok közötti megfelelést tükrözik, és szöveges információk kódolására és dekódolására szolgálnak. Szöveges információ számítógép-billentyűzet segítségével történő bevitelekor minden bemeneti karakter kódolásra kerül, azaz numerikus kóddá alakítva, amikor a szöveges információt egy számítógépes kimeneti eszközre (kijelzőre, nyomtatóra vagy plotterre) adják ki, a képe a numerikus karakterkódból épül fel. . Egy adott numerikus kód hozzárendelése egy szimbólumhoz a különböző országok megfelelő szervezetei közötti megállapodás eredménye. Jelenleg nincs egyetlen univerzális kódtábla, amely megfelelne a különböző országok nemzeti ábécéinek betűinek.
A modern kódtáblázatok nemzetközi és nemzeti részeket tartalmaznak, azaz latin és nemzeti ábécé betűit, számokat, aritmetikai és írásjeleket, matematikai és vezérlőkaraktereket, valamint pszeudográfiai karaktereket tartalmaznak. A kódtábla nemzetközi része a szabvány alapján ASCII (amerikai szabványos információcsere kód), a kódtábla karaktereinek első felét 0-tól 7-ig terjedő számkódokkal kódolja F16, vagy decimális számrendszerben 0-tól 127-ig. Ebben az esetben a személyi számítógép billentyűzetének funkciógombjaihoz (F1, F2, F3 stb.) 0 és 20 16 (0 × 32 10) közötti kódok vannak hozzárendelve. ábrán A 3.1 a szabványon alapuló kódtáblázatok nemzetközi részét mutatja ASCII. A táblázat cellái decimális, illetve hexadecimális számrendszerben vannak számozva.

3.1. ábra. A kódtábla nemzetközi része (standard ASCII) a cellaszámokkal decimális (a) és hexadecimális (b) számrendszerben
A kódtáblázatok nemzeti része tartalmazza a nemzeti ábécék kódjait, amelyet karakterkészlet táblázatnak is neveznek. (karakterkészlet).
Jelenleg az orosz ábécé (cirill) betűinek támogatására számos kódtábla (kódolás) létezik, amelyeket különféle operációs rendszerek használnak, ami jelentős hátrány, és bizonyos esetekben problémákhoz vezet a számértékek dekódolási műveletei során. karakterekből. táblázatban. A 3.1 mutatja azoknak a kódlapoknak (szabványoknak) a nevét, amelyeken cirill kódtáblák (kódolások) vannak elhelyezve.
3.1. táblázat
Az egyik első szabvány a cirill kódolására a számítógépeken a KOI8-R szabvány volt. A szabvány kódtáblázatának nemzeti része a 2. ábrán látható. 3.2.

Rizs. 3.2. A KOI8-R szabvány kódtáblázatának nemzeti része
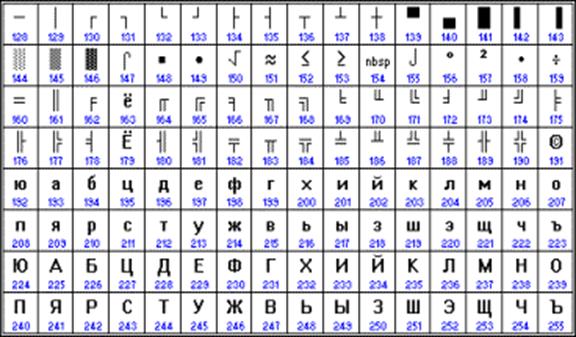
Jelenleg a kódtábla is használatos, amely az operációs rendszerben használt szöveges információs kódolási szabvány CP866 oldalán található. MS DOS vagy munkamenet MS DOS a cirill ábécé kódolásához (3.3. ábra, a)


Rizs. 3.3. A kódtábla nemzeti része, amely a szöveges információs kódolási szabvány СР866 (a) és СР1251 (b) oldalán található
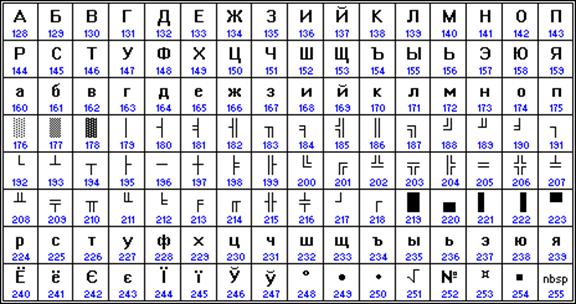
Jelenleg a cirill kódoláshoz a legszélesebb körben használt kódtábla a megfelelő szabvány СР1251 oldalán található, amelyet a család operációs rendszereiben használnak. ablakok cégek Microsoft(3.2. ábra, b). Minden bemutatott kódtáblázatban, kivéve a standard táblát Unicode, Egy karakter kódolásához 8 bit (8 bit) van lefoglalva.
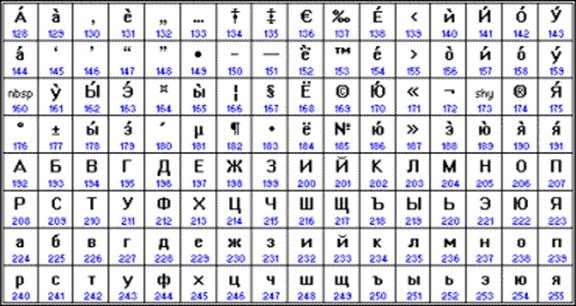
A múlt század végén új nemzetközi szabvány jelent meg Unicode, amelyben egy karaktert egy kétbájtos bináris kód képvisel. Ennek a szabványnak az alkalmazása egy univerzális nemzetközi szabvány fejlesztésének folytatása, amely lehetővé teszi a nemzeti karakterkódolások kompatibilitási problémájának megoldását. Ennek a szabványnak a használatával 2 16 = 65536 különböző karakter kódolható. ábrán A 3.4 a szabvány 0400 (orosz ábécé) kódtáblázatát mutatja Unicode.
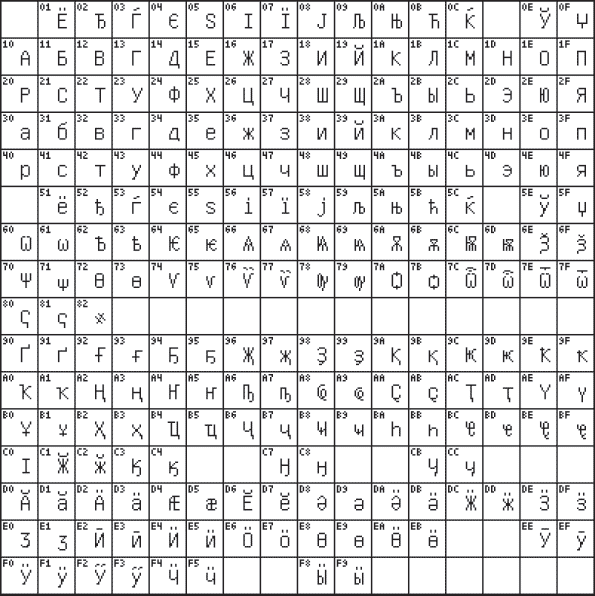
Rizs. 3.4. Az Unicode szabvány 0400 kódtáblázata
Magyarázzuk meg a szöveges információk kódolásával kapcsolatban elmondottakat egy példán keresztül.
Példa 3.1Kódolja a „Számítógép” szót decimális és hexadecimális számok sorozataként a CP1251 kódolással. Milyen karakterek jelennek meg az SR866 és KOI8-R kódtáblázatban a fogadott kód használatakor.
Hexadecimális és bináris kódsorozatok a "Számítógép" szóhoz a CP1251 kódtáblázat alapján (lásd: 3.3. ábra, b)így fog kinézni:
Ez a CP866 és KOI8-R kódolású kódsorozat a következő karaktereket jeleníti meg:
Az orosz nyelvű szöveges dokumentumok egyik szöveginformációs kódolási szabványról a másikra konvertálásához speciális programokat használnak - konvertereket. Az átalakítókat általában más programokba építik be. Példa erre egy böngészőprogram - Internet Explorer (IE) amely beépített konverterrel rendelkezik. A böngészőprogram egy speciális program a tartalom megtekintésére weboldalak az Internet globális számítógépes hálózatában. Használjuk ezt a programot a 3.1. példában kapott karakterleképezés eredményének megerősítésére. Ehhez hajtsa végre a következő lépéseket.
1. Futtassa a Jegyzettömböt (Jegyzettömb). Jegyzettömb program az operációs rendszerben Windows XP a következő paranccsal indul el: [Button Rajt– Programok – Tartozékok – Jegyzettömb]. A megnyíló Jegyzettömb program ablakába írja be a "Számítógép" szót a hipertext dokumentum jelölőnyelvének szintaxisával - HTML (Hyper Text Markup Language). Ezt a nyelvet használják dokumentumok létrehozására az interneten. A szövegnek így kell kinéznie:
Számítógép
, aholés
a nyelv címkéi (speciális konstrukciói). HTML címsorokhoz. ábrán A 3.5 mutatja ezeknek a műveleteknek az eredményét.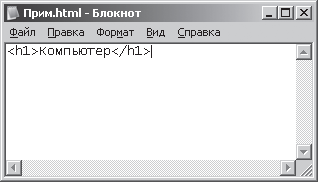
Rizs. 3.5. Szöveg megjelenítése a Jegyzettömb ablakában
Mentsük el ezt a szöveget a következő parancs végrehajtásával: [Fájl - Mentés másként...] a számítógép megfelelő mappájába, a szöveg mentésekor a fájlnak nevet adunk - Megjegyzés, a fájl kiterjesztésével. html.
2. Futtassa a programot internet böngésző, parancs végrehajtásával: [Button Rajt- Programok - Internet böngésző]. A program indításakor az ábrán látható ablak jelenik meg. 3.6
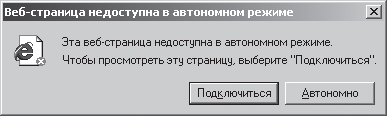
Rizs. 3.6. Offline hozzáférési ablak
Válassza ki és aktiválja a gombot Offline ez nem csatlakoztatja a számítógépet a globális internethez. Megjelenik a program főablakja Microsoft Internet Explorer,ábrán látható. 3.7.
Rizs. 3.7. Microsoft Internet Explorer főablak
Végezzük el a következő parancsot: [Fájl - Megnyitás], megjelenik egy ablak (3.8. ábra), amelyben meg kell adni a fájl nevét, és kattintson a gombra. rendben vagy nyomja meg a gombot Áttekintés…és keresse meg a Note.html fájlt.

Rizs. 3.8. Nyitott ablak
Az Internet Explorer program fő ablaka az ábrán látható formában jelenik meg. 3.9. Az ablakban megjelenik a „Számítógép” szó. Ezután használja a program felső menüjét internet böngésző, futtassa a következő parancsot: [Nézet - Kódolás - Cirill (DOS)]. A parancs végrehajtása után a program ablakában internet böngészőábrán látható szimbólumok. 3.10. A parancs végrehajtásakor: [Nézet - Kódolás - Cirill (KOI8-R)] a program ablakában internet böngészőábrán látható szimbólumok. 3.11.

Rizs. 3.9. A karakterek CP1251 kódolással jelennek meg
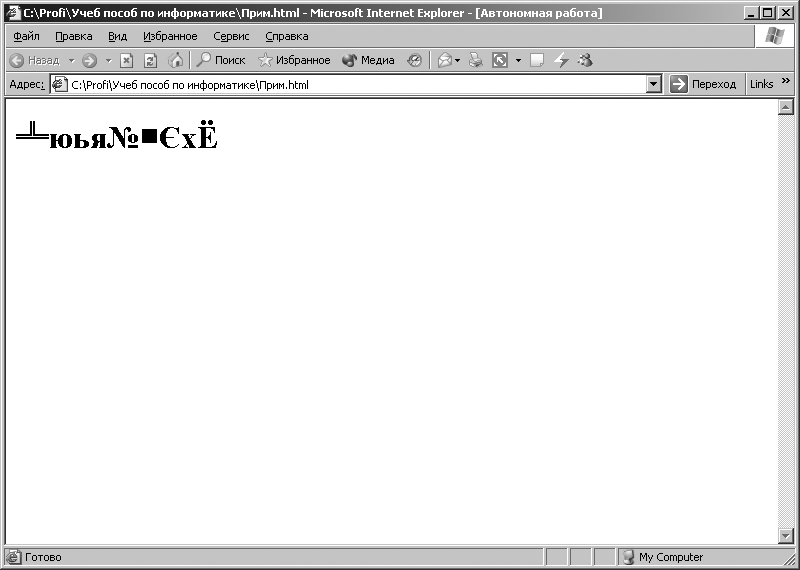
Rizs. 3.10. Karakterek, amelyek akkor jelennek meg, ha a CP866 kódolás engedélyezve van a CP1251 kódolású kódsorozathoz
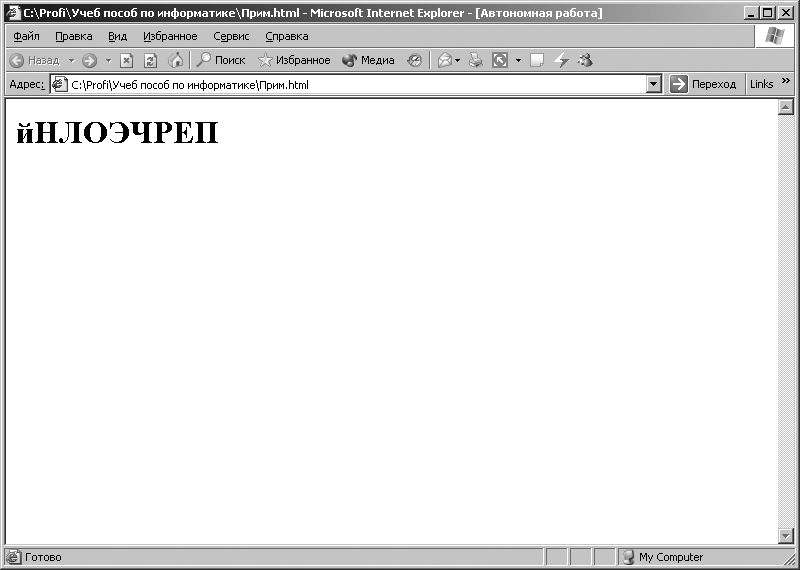
Rizs. 3.11. Karakterek, amelyek akkor jelennek meg, ha a KOI8-R kódolás engedélyezve van a CP1251 kódolásban szereplő kódsorozathoz
Így kapott a program segítségével internet böngésző a karaktersorozatok megegyeznek a 3.1. példában a CP866 és KOI8-R kódtáblázatokkal kapott karaktersorozatokkal.
3.2. Grafikus információk kódolása
A rajzok, fényképek, diaképek, mozgóképek (animáció, videó), diagramok, rajzok formájában megjelenített grafikus információk számítógéppel készíthetők és szerkeszthetők, megfelelő kódolás mellett. Jelenleg elég nagyszámú grafikus információk feldolgozására szolgáló alkalmazási programok, de mindegyik három típusú számítógépes grafikát valósít meg: raszteres, vektoros és fraktál.
Ha közelebbről megnézi a grafikus képet a számítógép-monitor képernyőjén, nagyszámú többszínű pont (pixel - angolul) látható. pixel,-ből alakult ki kép elem képelem), amelyek összerakva alkotják az adott grafikai képet. Ebből arra következtethetünk: a számítógépben lévő grafikus kép bizonyos módon kódolt, és grafikus fájlként kell bemutatni. A fájl a fő szerkezeti egység az adatok számítógépben történő rendszerezéséhez és tárolásához, és ebben az esetben információkat kell tartalmaznia arról, hogyan jeleníthető meg ez a pontkészlet a monitor képernyőjén.
A vektorgrafika alapján létrehozott fájlok matematikai függőségek (lineáris függőségeket leíró matematikai függvények) és kapcsolódó adatok formájában tartalmaznak információkat arról, hogyan lehet egy objektumról képet készíteni vonalszakaszok (vektorok) segítségével, amikor azokat a számítógép-monitor képernyőjén jelenítik meg.
A rasztergrafika alapján létrehozott fájlok a kép minden egyes pontjáról adattárolást feltételeznek. A rasztergrafikus megjelenítés nem igényel bonyolult matematikai számításokat, elég, ha a kép egyes pontjairól (koordinátáiról és színeiről) adatokat szerezünk és megjelenítjük a számítógép monitorán.
A képkódolás során ennek térbeli mintavételezése történik, azaz a képet külön pontokra osztják, és minden ponthoz színkódot adnak (sárga, piros, kék stb.). A színes grafikus kép minden pontjának kódolásához egy tetszőleges szín fő összetevőire való felosztásának elvét alkalmazzák, amelyek három alapszínként használatosak: piros (angol szó piros, betűvel jelöljük NAK NEK), zöld (zöld, betűvel jelöljük G), kék (Kék, bükk kijelölése V). Az emberi szem által észlelt bármely pontszín a három alapszín - vörös, zöld és kék - additív (arányos) hozzáadásával (keverésével) nyerhető. Ezt a kódrendszert színrendszernek nevezik. RGB. Színrendszert használó képfájlok RGB,ábrázolja a kép minden pontját színhármasként – három számértéket R, Gés V, intenzitásának megfelelő vörös, zöld és kék virágok. A grafikus kép kódolásának folyamata különféle technikai eszközökkel történik (szkenner, digitális fényképezőgép, digitális videokamera stb.); az eredmény egy bittérképes kép. Ha színes grafikus képeket játszik le egy színes számítógép-monitor képernyőjén, az ilyen kép minden pontjának (pixeljének) színét három elsődleges szín keverésével kapjuk meg. R,Gés b.
A raszteres kép minőségét két fő paraméter határozza meg - a felbontás (a vízszintes és függőleges pontok száma) és a használt színpaletta (az egyes képpontokhoz megadott színek száma). A felbontást a vízszintes és függőleges pontok számának megadásával lehet megadni, például 800 x 600 pont.
Összefüggés van a raszteres kép egy pixeléhez rendelt színek száma és a képpont színének tárolásához hozzárendelendő információ mennyisége között, amelyet az arány határozza meg (R. Hartley képlete):
ahol én– információ mennyisége; N- pontnak adott színek száma.
A pont színének tárolásához szükséges információmennyiséget színmélységnek vagy színminőségnek is nevezik.
Így ha egy képponthoz megadott színek száma az N= 256, akkor a tárolásához szükséges információ mennyisége (színmélysége) a (3.1) képlet szerint egyenlő lesz én= 8 bit.
A számítógépek különféle grafikus megjelenítési módokat használnak a grafikus információk megjelenítésére. Itt kell megjegyezni, hogy a monitor grafikus üzemmódja mellett van egy szöveges mód is, amelyben a monitor képernyője hagyományosan 25 sorra van felosztva, soronként 80 karakterből áll. Ezeket a grafikus módokat a monitor képernyőfelbontása és a színminőség (színmélység) jellemzi. A monitor képernyő grafikus üzemmódjának beállítása az operációs rendszerben MS Windows XP a következő parancsot kell végrehajtania: [Button Rajt– Beállítások – Vezérlőpult – Kijelző]. A megjelenő "Tulajdonságok: Kijelző" párbeszédpanelen (3.12. ábra) válassza ki a "Paraméterek" fület, és a "Képernyőfelbontás" csúszkával válassza ki a megfelelő képernyőfelbontást (800x600 pixel, 1024x768 pixel stb.). A "Színminőség" legördülő listából kiválaszthatja a színmélységet - "Legmagasabb (32 bit)", "Közepes (16 bit)" stb., miközben a kép egyes pontjaihoz rendelt színek száma 2 32 (4294967296), 2 16 (65536) stb.

Rizs. 3.12. Megjelenítés tulajdonságai párbeszédpanel
A monitor képernyőjének mindegyik grafikus üzemmódjának megvalósításához a számítógép videomemóriájának bizonyos információmennyisége szükséges. A videomemória szükséges információmennyisége (V) arányból határozzuk meg
ahol NAK NEK - a képpontok száma a monitor képernyőjén (K = A B); A - a vízszintes pontok száma a monitor képernyőjén; V - a függőleges pontok száma a monitor képernyőjén; én– információ mennyisége (színmélység).
Tehát, ha a monitor képernyőjének felbontása 1024 x 768 pixel és a paletta 65 536 színből áll, akkor a színmélység a (3.1) képlet szerint I = log 2 65 538 = 16 bit, a képpontok száma lenni: K = 1024 x 768 = 786432, és a videomemória szükséges információmennyisége a (3.2) szerint egyenlő lesz
V = 786432 16 bit = 12582912 bit = 1572864 bájt = 1536 KB = 1,5 MB.
Összegzésként meg kell jegyezni, hogy a felsorolt jellemzők mellett a monitor legfontosabb jellemzői a képernyő és a képpontok geometriai méretei. A képernyő geometriai méreteit a monitor átlójának mérete határozza meg. A monitorok átlója hüvelykben (1 hüvelyk = 1" = 25,4 mm) van beállítva, és a következő értékeket vehet fel: 14", 15", 17", 21" stb. A modern monitorgyártási technológiák képesek képpontméretet biztosítani egyenlő 0,22 mm-rel.
Így minden monitorhoz van egy fizikailag maximálisan lehetséges képernyőfelbontás, amelyet az átlója és a képpont mérete határoz meg.
Gyakorlatok az önmegvalósításhoz
1. A program használata MS Excel konvertálja az ASCII, СР866, СР1251, KOI8-R kódtáblázatokat a következő alakú táblázatokká: a táblázatok első oszlopának celláiba írja be ábécé sorrendben a nagybetűket, majd a kisbetűket latin és cirill betűkkel, a második oszlop celláiba - a tizedes számrendszer betűinek megfelelő kódokat, a cellákban a harmadik oszlopot - a hexadecimális számrendszer betűinek megfelelő kódokat. A kódértékeket a megfelelő kódtáblázatokból kell kiválasztani.
2. Kódolja és írja le a következő szavakat számsorként decimális és hexadecimális jelöléssel:
a) internet böngésző, b) Microsoft Office v) Corel Draw.
Kódolás az előző gyakorlatban kapott frissített ASCII kódolási táblázat felhasználásával történő előállításához.
3. Dekódolja a frissített KOI8-R kódtáblázat segítségével a hexadecimális számrendszerben írt számsorozatokat:
a) FC CB DA C9 D3 D4 C5 CE C3 C9 D1;
b) EB CF CE C6 CF D2 CD C9 DA CD;
c) FC CB D3 D0 D2 C5 D3 C9 CF CE C9 DA CD.
4. Hogyan fog kinézni a CP1251 kódolással írt "Cybernetics" szó a CP866 és KOI8-R kódolás használatakor? Ellenőrizze az eredményeket a programmal Internet böngésző.
5. ábrán látható kódtáblázat segítségével. 3.1 a, dekódolja a következő bináris jelöléssel írt kódsorozatokat:
a) 01010111 01101111 01110010 01100100;
b) 01000101 01111000 01100011 01100101 01101100;
c) 01000001 01100011 01100011 01100101 01110011 01110011.
6. Határozza meg az "Economy" szó információmennyiségét a СР866, СР1251, Unicode és KOI8-R kódtáblázatok segítségével.
7. Határozza meg a 12x12 cm-es színes kép beszkennelésével kapott fájl információs mennyiségét A kép beolvasásához használt szkenner felbontása 600 dpi! A szkenner a képpont színmélységét 16 bitre állítja be.
Szkenner felbontása 600 dpi (pont hüvelyk - pont/hüvelyk) határozza meg, hogy egy ilyen felbontású lapolvasó képes-e megkülönböztetni 600 pontot egy 1 hüvelykes szegmensen.
8. Határozza meg az A4-es méretű színes kép szkennelésével kapott fájl információs mennyiségét! A kép beolvasásához használt szkenner felbontása 1200 dpi. A szkenner a képpont színmélységét 24 bitre állítja be.
9. Határozza meg a színek számát a palettán 8, 16, 24 és 32 bites színmélység mellett!
10. Határozza meg a szükséges videomemória mennyiségét a 640 x 480, 800 x 600, 1024 x 768 és 1280 x 1024 képpontos monitor képernyő grafikus üzemmódjaihoz 8, 16, 24 és 32 bites képpont színmélységgel. Az eredményeket táblázatban foglaljuk össze. Fejlődj be MS Excel program a számítások automatizálására.
11. Határozza meg a 32 x 32 pixeles kép tárolására használható színek maximális számát, ha a számítógép 2 KB memóriát különített el a kép számára.
12. Határozza meg a 15 hüvelykes átlójú és 0,28 mm-es képpontméretű monitor maximális lehetséges képernyőfelbontását.
13. A monitor milyen grafikus működési módjait tudja biztosítani a 64 MB videomemória?
Anyag önálló tanuláshoz a témában 2. előadás
Kódolás ASCII
ASCII kódolási táblázat (ASCII - American Standard Code for Information Interchange - American Standard Code for Information Interchange).
Összességében az ASCII kódolási táblázat segítségével (1. ábra) 256 különböző karakter kódolható. Ez a táblázat két részre oszlik: fő (OOh-tól 7Fh-ig kódokkal) és kiegészítő (80h-tól FFh-ig terjedő kódokkal, ahol a h betű azt jelzi, hogy a kód a hexadecimális számrendszerhez tartozik).
1. kép
A táblázat egy karakterének kódolásához 8 bit (1 bájt) van lefoglalva. Szöveges információ feldolgozása során egy bájt tartalmazhat néhány karakter kódját - betűket, számokat, írásjeleket, műveletjeleket stb. Minden karakternek saját kódja van egész szám formájában. Ebben az esetben az összes kódot speciális táblákba gyűjtik, amelyeket kódolási tábláknak neveznek. Segítségükkel a karakterkód a monitor képernyőjén látható reprezentációjává alakul át. Ennek eredményeként a számítógép memóriájában lévő bármely szöveg bájtok sorozataként jelenik meg karakterkódokkal.
Például a hello szó! a következőképpen lesz kódolva (1. táblázat).
Asztal 1
|
Bináris kód | ||||||
|
Kód decimális |
Az 1. ábra a szabványos (angol) és a kiterjesztett (orosz) ASCII-kódolásban szereplő karaktereket mutatja.
Az ASCII tábla első fele szabványosított. Vezérlőkódokat tartalmaz (00h és 20h és 77h között). Ezeket a kódokat eltávolítottuk a táblázatból, mert nem vonatkoznak szöveges elemekre. Ide kerülnek az írásjelek és a matematikai jelek is: 2lh - !, 26h - &, 28h - (, 2Bh -+, ..., nagy és kis latin betűk: 41h - A, 61h - a.
A táblázat második felében nemzeti betűtípusok, pszeudográfiai szimbólumok, amelyekből táblázatok építhetők, speciális matematikai szimbólumok találhatók. A kódolási táblázat alsó része a megfelelő illesztőprogramokkal - vezérlő segédprogramokkal - cserélhető. Ez a technika lehetővé teszi több betűtípus és azok betűtípusának használatát.
Az egyes karakterkódok kijelzőjén a karakter képét kell megjeleníteni - nem csak egy digitális kódot, hanem egy hozzá tartozó képet is, mivel minden karakternek saját alakja van. Az egyes karakterek alakjának leírását egy speciális kijelzőmemória - egy karaktergenerátor - tárolja. Egy karakter kiemelése például az IBM PC képernyőjén karaktermátrixot alkotó pontok használatával történik. Az ilyen mátrixban minden pixel képelem, és lehet világos vagy sötét. A sötét pontokat 0, a világos (világos) egyet 1-gyel kódolja. Ha a sötét képpontokat egy pont jelzi a jel mátrixmezőjében, a világos pixeleket pedig egy csillag, akkor grafikusan ábrázolhatja az alakzatot. a szimbólumról.
Emberek különböző országok szimbólumokkal írják le anyanyelvük szavait. Manapság a legtöbb alkalmazás, beleértve az e-mail rendszereket és a webböngészőket is, tisztán 8 bites, ami azt jelenti, hogy az ISO-8859-1 szabvány szerint csak 8 bites karaktereket tudnak megjeleníteni és helyesen olvasni.
Több mint 256 karakter van a világon (beleértve a cirill, arab, kínai, japán, koreai és thai karaktereket), és egyre több karakter kerül hozzáadásra. Ez pedig a következő hiányosságokat okozza sok felhasználó számára:
Ugyanabban a dokumentumban nem lehet különböző kódolási készletekből származó karaktereket használni. Mivel minden szöveges dokumentum a saját kódolásait használja, az automatikus szövegfelismerés nagy nehézségeket okoz.
Új szimbólumok jelennek meg (például: Euro), melynek eredményeként az ISO új szabványt dolgoz ki, az ISO-8859-15, amely nagyon hasonlít az ISO-8859-1 szabványhoz. A különbség a következő: a régi, jelenleg nem használt pénznemek jelölésére szolgáló szimbólumokat eltávolítottuk a régi ISO-8859-1 szabvány kódolási táblázatából, hogy helyet adjunk az újonnan megjelenő szimbólumoknak (például az eurónak). Ennek eredményeként a felhasználók ugyanazokat a dokumentumokat tárolhatják a lemezeiken, de eltérő kódolásban. E problémák megoldása egyetlen nemzetközi kódolási készlet elfogadása, amelyet univerzális kódolásnak vagy Unicode-nak neveznek.
Kódolás Unicode
A szabványt 1991-ben a Unicode Consortium non-profit szervezet javasolta (angolul Unicode Consortium, Unicode Inc.). Ennek a szabványnak a használata nagyon sok karakter kódolását teszi lehetővé különböző írásokból: a kínai karakterek, matematikai szimbólumok, a görög ábécé betűi, a latin és a cirill ábécé együtt létezhetnek a Unicode dokumentumokban, miközben szükségtelenné válik a kódlapok váltása.
A szabvány két fő részből áll: az univerzális karakterkészletből (UCS, univerzális karakterkészlet) és a kódolási családból (UTF, Unicode transzformációs formátum). Az univerzális karakterkészlet a karakterek egy az egyhez megfeleltetését adja meg a kódoknak – a kódtér nemnegatív egész számokat képviselő elemeinek. Egy kódolási család határozza meg az UCS-kódok sorozatának gépi reprezentációját.
Az Unicode szabványt azzal a céllal fejlesztették ki, hogy egyetlen karakterkódolást hozzon létre az összes modern és sok ősi írott nyelv számára. Ebben a szabványban minden karakter 16 bittel van kódolva, ami lehetővé teszi, hogy összehasonlíthatatlanul több karaktert fedjen le, mint a korábban elfogadott 8 bites kódolások. Egy másik fontos különbség a Unicode és más kódolási rendszerek között, hogy nem csak egyedi kódot rendel minden karakterhez, hanem meghatározza a karakter különféle jellemzőit is, például:
karaktertípus (nagybetű, kisbetű, szám, írásjel stb.);
karakterattribútumok (balról jobbra vagy jobbról balra irányú megjelenítés, szóköz, sortörés stb.);
megfelelő nagy- vagy kisbetű (kis- és nagybetűk esetén);
a megfelelő számérték (numerikus karaktereknél).
A kódok teljes tartománya 0-tól FFFF-ig több szabványos részhalmazra van felosztva, amelyek mindegyike vagy valamelyik nyelv ábécéjének, vagy funkciójukban hasonló speciális karakterek csoportjának felel meg. Az alábbi diagram a Unicode 3.0 részhalmazainak általános listáját tartalmazza (2. ábra).

2. ábra
A Unicode szabvány sok modern számítógépes rendszerben a tárolás és a szöveg alapja. A legtöbb internetes protokollal azonban nem kompatibilis, mert kódjai bármilyen bájt értéket tartalmazhatnak, és a protokollok általában a 00 - 1F és az FE - FF bájtokat használják szolgáltatási bájtként. A kompatibilitás érdekében több Unicode transzformációs formátumot (UTF, Unicode Transformation Formats) fejlesztettek ki, amelyek közül ma az UTF-8 a legelterjedtebb. Ez a formátum a következő szabályokat határozza meg az egyes Unicode kódok bájtok (egytől háromig) való konvertálásához, amely alkalmas az internetes protokollok általi továbbításra.
Itt x,y,z jelöli a forráskód azon bitjeit, amelyeket a legkisebb szignifikánssal kezdve ki kell bontani, és jobbról balra kell bevinni az eredmény bájtjaiba, amíg az összes megadott pozíció ki nem töltődik.
Az Unicode szabvány további fejlesztése új nyelvi síkok hozzáadásával jár, pl. karakterek az 10000 - 1FFFF, 20000 - 2FFFF stb. tartományban, ahol a fenti táblázatban nem szereplő, halott nyelvek szkriptjeinek kódolását kell tartalmaznia. Egy új UTF-16 formátumot fejlesztettek ki ezen további karakterek kódolására.
Így 4 fő módja van a bájtok Unicode formátumban történő kódolásának:
UTF-8: 128 karakter egy bájtban kódolva (ASCII formátum), 1920 karakter 2 bájton kódolva ((római, görög, cirill, kopt, örmény, héber, arab karakterek), 63488 karakter 3 bájton kódolva (kínai, japán stb.) .) A fennmaradó 2 147 418 112 karakter (még nem használt) 4, 5 vagy 6 bájttal kódolható.
UCS-2: Minden karaktert 2 bájt képvisel. Ez a kódolás csak az első 65 535 karaktert tartalmazza a Unicode formátumból.
UTF-16: Ez az UCS-2 kiterjesztése, és 1 114 112 Unicode karaktert tartalmaz. Az első 65 535 karaktert 2 bájt, a többit 4 bájt képviseli.
USC-4: Minden karakter 4 bájttal van kódolva.
Szöveges információk kódolása
Vessünk egy pillantást az általunk ismert tényekre:
A szövegíráshoz használt szimbólumkészletet únbetűrendben.
Az ábécé karaktereinek száma aerő.
Az információ mennyiségének meghatározására szolgáló képlet:N=2b,
ahol N az ábécé hatványa (karakterek száma),
b - bitek száma (a szimbólum információs súlya).
Szinte az összes szükséges karakter elhelyezhető egy 256 karakteres ábécében. Ezt az ábécét hívjákelegendő.
Mivel 256 = 28 , akkor 1 karakter súlya 8 bit.
A 8 bites mértékegység nevet kapott1 bájt:
1 bájt = 8 bit.
A számítógépes szöveg minden egyes karakterének bináris kódja 1 bájt memóriát foglal el.
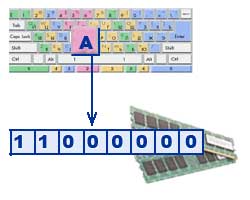
Hogyan jelennek meg a szöveges információk a számítógép memóriájában?
|
| A szövegek a billentyűzet segítségével kerülnek be a számítógép memóriájába. A billentyűket számunkra ismerős betűk, számok, írásjelek és egyéb szimbólumok írják. Bináris kódban írják be a RAM-ot. Ez azt jelenti, hogy minden karaktert egy 8 bites bináris kód képvisel. A kódolás abból áll, hogy minden karakterhez egyedi decimális kódot rendelnek 0-tól 255-ig, vagy a megfelelő bináris kódot 00000000-tól 11111111-ig. Így az ember a karaktereket stílusuk, a számítógép pedig a kódja alapján különbözteti meg. |

A karakterek bájtonkénti kódolásának kényelme nyilvánvaló, hiszen a bájt a memória legkisebb címezhető része, így a processzor a szövegfeldolgozás során minden karaktert külön tud elérni. Másrészt 256 karakter elég sokféle karakterinformáció megjelenítéséhez.
Felmerül a kérdés, hogy melyik nyolc bites bináris kódot kell megfeleltetni az egyes karakterekkel.
Nyilvánvaló, hogy ez egy feltételes ügy, sokféle kódolási módot találhatsz ki.
A számítógépes ábécé minden szimbóluma 0-tól 255-ig van számozva. Mindegyik szám egy nyolcjegyű bináris kódnak felel meg 00000000 és 11111111 között. Ez a kód egyszerűen a karakter sorszáma a bináris számrendszerben.
Az olyan táblázatot, amelyben a számítógép ábécéjének minden karakteréhez sorszám van hozzárendelve, kódolási táblázatnak nevezzük.
Mert különböző típusok A számítógép különféle kódolási táblákat használ.
Az asztal a PC-k nemzetközi szabványává vált.ASCII(ejtsd: asci) (American Standard Code for Information Interchange).
Az ASCII kódtábla két részre oszlik.
Csak a táblázat első fele nemzetközi szabvány, i.e. karakterek számokkal innen0 (00000000), legfeljebb127 (01111111).
Táblázat szerkezete ASCII kódolások
| Sorozatszám | A kód | Szimbólum |
| 0 - 31 | 00000000 - 00011111 | A 0 és 31 közötti számokat tartalmazó karaktereket vezérlőkaraktereknek nevezzük. |
| 32 - 127 | 00100000 - 01111111 | A táblázat szabványos része (angol). Ide tartoznak a latin ábécé kis- és nagybetűi, decimális számjegyek, írásjelek, mindenféle zárójelek, kereskedelmi és egyéb szimbólumok. |
| 128 - 255 | 10000000 - 11111111 | A táblázat alternatív része (orosz). |
Az ASCII kódtábla első fele
|
|

Felhívom a figyelmet arra, hogy a kódolási táblázatban a betűk (nagy- és kisbetűk) ábécé, a számok pedig növekvő sorrendben vannak. A lexikográfiai sorrendnek ezt a betartását a karakterek elrendezésében az ábécé szekvenciális kódolásának elvének nevezzük.
Az orosz ábécé betűinél a szekvenciális kódolás elvét is betartják.
Az ASCII kódtábla második fele

Sajnos jelenleg öt különböző cirill kódolás létezik (KOI8-R, Windows. MS-DOS, Macintosh és ISO). Emiatt gyakran problémák merülnek fel az orosz szöveg egyik számítógépről a másikra történő átvitelével, egyik szoftverrendszerről a másikra.
Kronológiailag az egyik első szabvány az orosz betűk számítógépeken történő kódolására a KOI8 ("8 bites információcsere kód") volt. Ezt a kódolást már a 70-es években használták az EC sorozatú számítógépeken, és a 80-as évek közepétől kezdték használni a UNIX operációs rendszer első oroszosított verzióiban.
A 90-es évek elejétől, az MS DOS operációs rendszer dominanciájának idejétől a kódolás továbbra is CP866 (a "CP" a "Code Page", "code page" rövidítése).
A Mac OS operációs rendszert futtató Apple számítógépek saját Mac kódolást használnak.
Ezenkívül a Nemzetközi Szabványügyi Szervezet (International Standards Organisation, ISO) egy másik, ISO 8859-5 nevű kódolást is jóváhagyott az orosz nyelv szabványaként.
A jelenleg leggyakrabban használt kódolás a Microsoft Windows, rövidítve CP1251.
A 90-es évek vége óta a karakterkódolás szabványosításának problémáját egy új nemzetközi szabvány bevezetése oldotta meg, amely az ún.Unicode. Ez egy 16 bites kódolás, azaz. karakterenként 2 bájt memóriája van. Természetesen ebben az esetben az elfoglalt memória mennyisége 2-szeresére nő. De egy ilyen kódtábla legfeljebb 65 536 karakter felvételét teszi lehetővé. A Unicode szabvány teljes specifikációja tartalmazza a világ összes létező, kihalt és mesterségesen létrehozott ábécéjét, valamint számos matematikai, zenei, kémiai és egyéb szimbólumot.
Próbáljuk meg egy ASCII tábla segítségével elképzelni, hogyan fognak kinézni a szavak a számítógép memóriájában.
Szavak belső ábrázolása a számítógép memóriájában
| A szavak | memória |
| fájlt | 01100110 01101001 01101100 01100101 |
| korong | 01100100 01101001 01110011 01101011 |
Néha megesik, hogy az orosz ábécé betűiből álló szöveget, amelyet egy másik számítógépről kaptunk, nem lehet elolvasni - a monitor képernyőjén valamiféle "abrakadabra" látható. Ez annak a ténynek köszönhető, hogy a számítógépek az orosz nyelv eltérő karakterkódolásait használják.
Tartalom
I. Az információs kódolás története…………………………………..3
II. Kódolási információ……………………………………………4
III. Szöveges információk kódolása……………………………….4
IV. A kódoló táblák típusai…………………………………………………6
V. Szöveges információ mennyiségének számítása……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
Felhasznált irodalom jegyzéke……………………………………..16
én . Információk kódolási előzményei
Az emberiség attól a pillanattól kezdve alkalmaz szövegtitkosítást (kódolást), amikor az első titkos információ megjelent. Íme néhány szövegkódolási technika, amelyeket az emberi gondolkodás fejlődésének különböző szakaszaiban találtak fel:
A kriptográfia kriptográfia, az írás megváltoztatásának rendszere annak érdekében, hogy a szöveg érthetetlen legyen az avatatlan személyek számára;
Morse-kód vagy nem egységes távírókód, amelyben minden betűt vagy karaktert rövid elemi parcellák saját kombinációja képvisel elektromos áram(pontok) és hármas időtartamú elemi parcellák (kötőjelek);
 A jelnyelv a hallássérült emberek által használt jelnyelv.
A jelnyelv a hallássérült emberek által használt jelnyelv. Az egyik legelső ismert módszerek a titkosítás Julius Caesar római császár nevét viseli (Kr. e. I. század). Ez a módszer azon alapul, hogy a titkosított szöveg minden betűjét lecseréljük egy másik betűre úgy, hogy az ábécét az eredeti betűtől meghatározott számú karakterrel eltolja, és az ábécét körben olvassuk be, vagyis az i betű után az a-t veszik figyelembe. Tehát a "byte" szót két karakterrel jobbra tolva a "gvlf" szó kódolja. Egy adott szó megfejtésének fordított folyamata az, hogy minden titkosított betűt lecserélünk a tőle balra lévő másodikra.
II. Információk kódolása
A kód konvenciók (vagy jelek) halmaza bizonyos előre meghatározott fogalmak rögzítésére (vagy továbbítására).
Az információ kódolása az információ bizonyos reprezentációjának kialakításának folyamata. Szűkebb értelemben a "kódolás" kifejezést gyakran az információmegjelenítés egyik formájából a másikba való átmenetként értik, amely kényelmesebb tárolás, továbbítás vagy feldolgozás szempontjából.
Általában minden egyes képet kódolva (néha azt mondják - titkosítva) külön karakter képviseli.
A jel különálló elemek véges halmazának eleme.
Szűkebb értelemben a "kódolás" kifejezést gyakran az információmegjelenítés egyik formájából a másikba való átmenetként értik, amely kényelmesebb tárolás, továbbítás vagy feldolgozás szempontjából.
A számítógép képes szöveges információkat feldolgozni. A számítógépbe beírva minden betű egy bizonyos számmal van kódolva, külső eszközökre (képernyő vagy nyomtatás) pedig az emberi érzékelés érdekében a betűk képei ezekből a számokból épülnek fel. A betűk és számok halmaza közötti megfelelést karakterkódolásnak nevezzük.
Általános szabály, hogy a számítógépen lévő összes számot nullákkal és egyesekkel ábrázolják (és nem tíz számjegyből, ahogy az embereknél szokás). Más szóval, a számítógépek általában bináris rendszerben működnek, mivel a feldolgozó eszközök sokkal egyszerűbbek. A számok számítógépbe bevitele és emberi olvasásra való kiadása a megszokott decimális formában történhet, és minden szükséges átalakítást a számítógépen futó programok hajtanak végre.
III. Szöveges információk kódolása
Ugyanaz az információ többféle formában is bemutatható (kódolható). A számítógépek megjelenésével szükségessé vált minden olyan információ kódolása, amellyel az egyén és az emberiség egésze foglalkozik. De az emberiség már jóval a számítógépek megjelenése előtt elkezdte megoldani az információ kódolásának problémáját. Az emberiség grandiózus vívmányai - az írás és a számtan - nem más, mint a beszéd és a numerikus információk kódoló rendszere. Az információ soha nem jelenik meg tiszta formájában, mindig valamilyen módon bemutatásra kerül, valamilyen módon kódolva.
A bináris kódolás az információ megjelenítésének egyik leggyakoribb módja. Számítógépekben, robotokban és numerikus vezérlésű szerszámgépekben általában az összes információ, amellyel az eszköz foglalkozik, bináris ábécé szavak formájában van kódolva.
A 60-as évek vége óta a számítógépeket egyre gyakrabban használják szöveges információk feldolgozására, és jelenleg a személyi számítógépek túlnyomó részét (és legtöbbször) szöveges információk feldolgozása foglalja el a világon. A számítógépben az összes ilyen típusú információ bináris kódban van ábrázolva, azaz kettős hatványú ábécét használnak (csak két karakter 0 és 1). Ez annak köszönhető, hogy kényelmes az információt elektromos impulzusok sorozata formájában ábrázolni: nincs impulzus (0), van impulzus (1).
Az ilyen kódolást általában binárisnak nevezik, magukat a nullák és egyesek logikai sorozatait pedig gépi nyelvnek.
A számítógép szempontjából a szöveg egyedi karakterekből áll. A karakterek között nemcsak betűk (nagybetűk vagy kisbetűk, latin vagy orosz) szerepelnek, hanem számok, írásjelek, speciális karakterek, például "=", "(", "&" stb.), sőt (különösen figyeljen!) szóközök is a szavak között .
A szövegek a billentyűzet segítségével kerülnek be a számítógép memóriájába. A billentyűket számunkra ismerős betűk, számok, írásjelek és egyéb szimbólumok írják. Bináris kódban írják be a RAM-ot. Ez azt jelenti, hogy minden karaktert egy 8 bites bináris kód képvisel.
 Hagyományosan egy karakter kódolásához 1 bájtnak megfelelő információmennyiséget használnak, azaz I \u003d 1 bájt \u003d 8 bit. A lehetséges események K számát és az I információ mennyiségét összeállító képlet segítségével kiszámítható, hogy hány különböző karakter kódolható (feltételezve, hogy a karakterek lehetséges események): K = 2 I = 2 8 = 256, azaz szöveges információ megjelenítésére használhatja a 256 karakteres ábécét.
Hagyományosan egy karakter kódolásához 1 bájtnak megfelelő információmennyiséget használnak, azaz I \u003d 1 bájt \u003d 8 bit. A lehetséges események K számát és az I információ mennyiségét összeállító képlet segítségével kiszámítható, hogy hány különböző karakter kódolható (feltételezve, hogy a karakterek lehetséges események): K = 2 I = 2 8 = 256, azaz szöveges információ megjelenítésére használhatja a 256 karakteres ábécét. Ez a karakterszám elég a szöveges információk megjelenítéséhez, beleértve az orosz és latin ábécé kis- és nagybetűit, számokat, jeleket, grafikus szimbólumokat stb.
A kódolás abból áll, hogy minden karakterhez egyedi decimális kódot rendelnek 0-tól 255-ig, vagy a megfelelő bináris kódot 00000000-tól 11111111-ig. Így az ember a karaktereket stílusuk alapján, a számítógép pedig a kódjuk alapján különbözteti meg.
A karakterek bájtonkénti kódolásának kényelme nyilvánvaló, hiszen a bájt a memória legkisebb címezhető része, így a processzor a szövegfeldolgozás során minden karaktert külön tud elérni. Másrészt 256 karakter elég sokféle karakterinformáció megjelenítéséhez.
A karakter számítógép képernyőjén történő megjelenítése során fordított folyamatot hajtanak végre - dekódolást, vagyis a karakterkódot képpé alakítják. Fontos, hogy egy adott kód hozzárendelése egy szimbólumhoz megegyezés kérdése, amit a kódtáblázatban rögzítünk.
Felmerül a kérdés, hogy melyik nyolc bites bináris kódot kell megfeleltetni az egyes karakterekkel. Nyilvánvaló, hogy ez egy feltételes ügy, sokféle kódolási módot találhatsz ki.
A számítógépes ábécé minden szimbóluma 0-tól 255-ig van számozva. Minden szám egy nyolcjegyű bináris kódnak felel meg 00000000 és 11111111 között. Ez a kód egyszerűen a karakter sorszáma a bináris számrendszerben.
IV . A kódoló táblák típusai
Az olyan táblázatot, amelyben a számítógép ábécéjének minden karakteréhez sorszám van hozzárendelve, kódolási táblázatnak nevezzük.
A különböző típusú számítógépekhez különböző kódolási táblázatokat használnak.
Az ASCII (American Standard Code for Information Interchange) kódtáblázatot nemzetközi szabványként fogadják el, amely a karakterek első felét 0-tól 127-ig terjedő számkódokkal kódolja (a 0-tól 32-ig terjedő kódok nem karakterekhez, hanem funkcióbillentyűkhöz vannak rendelve).
Az ASCII kódtábla két részre oszlik.
Csak a táblázat első fele nemzetközi szabvány, i.e. karakterek 0 (00000000) és 127 (01111111) közötti számokkal.
Az ASCII kódolótábla felépítése
| Sorozatszám | A kód | Szimbólum |
| 0 - 31 | 00000000 - 00011111 | A 0 és 31 közötti számokat tartalmazó karaktereket vezérlőkaraktereknek nevezzük. Feladatuk a szöveg képernyőn való megjelenítésének vagy nyomtatásának, hangjelzésének, szövegjelölésének stb. |
| 32 - 127 | 0100000 - 01111111 | A táblázat szabványos része (angol). Ide tartoznak a latin ábécé kis- és nagybetűi, decimális számjegyek, írásjelek, mindenféle zárójelek, kereskedelmi és egyéb szimbólumok. A 32. karakter egy szóköz, azaz. üres hely a szövegben. A többit bizonyos jelek tükrözik. |
| 128 - 255 | 10000000 - 11111111 | A táblázat alternatív része (orosz). Az ASCII kódtábla második fele, az úgynevezett kódlap (128 kód, 10000000-től 11111111-ig végződő), különböző opciókat tartalmazhat, mindegyik opciónak saját száma van. A kódlap elsősorban a latintól eltérő nemzeti betűk elhelyezésére szolgál. Az orosz nemzeti kódolásoknál az orosz ábécé karakterei a táblázat ezen részében vannak elhelyezve. |

Az ASCII kódtábla első fele
Felhívjuk a figyelmet arra, hogy a kódolási táblázatban a betűk (nagy- és kisbetűk) ábécé, a számok pedig növekvő sorrendben vannak. A lexikográfiai sorrendnek ezt a betartását a karakterek elrendezésében az ábécé szekvenciális kódolásának elvének nevezzük.
Az orosz ábécé betűinél a szekvenciális kódolás elvét is betartják.
Az ASCII kódtábla második fele
Sajnos jelenleg öt különböző cirill kódolás létezik (KOI8-R, Windows. MS-DOS, Macintosh és ISO). Emiatt gyakran problémák merülnek fel az orosz szöveg egyik számítógépről a másikra történő átvitelével, egyik szoftverrendszerről a másikra.
Kronológiailag az egyik első szabvány az orosz betűk számítógépeken történő kódolására a KOI8 ("8 bites információcsere kód") volt. Ezt a kódolást már a 70-es években használták az EC sorozatú számítógépeken, és a 80-as évek közepétől kezdték használni a UNIX operációs rendszer első oroszosított verzióiban.
A 90-es évek elejétől, az MS DOS operációs rendszer dominanciájának idejétől a kódolás továbbra is CP866 (a "CP" a "Code Page", "code page" rövidítése).
A Mac OS operációs rendszert futtató Apple számítógépek saját Mac kódolást használnak.

Ezenkívül a Nemzetközi Szabványügyi Szervezet (International Standards Organisation, ISO) egy másik, ISO 8859-5 nevű kódolást is jóváhagyott az orosz nyelv szabványaként.

A jelenleg leggyakrabban használt kódolás a Microsoft Windows, rövidítve CP1251. Bevezette a Microsoft; tekintettel a vállalat operációs rendszereinek (OS) és egyéb szoftvertermékeinek széles körű terjesztésére Orosz Föderáció elterjedtté vált.
A 90-es évek vége óta a karakterkódolás szabványosításának problémáját egy új nemzetközi szabvány, az Unicode bevezetése oldotta meg.

Ez egy 16 bites kódolás, azaz. karakterenként 2 bájt memóriája van. Természetesen ebben az esetben az elfoglalt memória mennyisége 2-szeresére nő. De egy ilyen kódtábla legfeljebb 65 536 karakter felvételét teszi lehetővé. A Unicode szabvány teljes specifikációja tartalmazza a világ összes létező, kihalt és mesterségesen létrehozott ábécéjét, valamint számos matematikai, zenei, kémiai és egyéb szimbólumot.
Szavak belső ábrázolása a számítógép memóriájában
ASCII tábla segítségével
Néha megesik, hogy az orosz ábécé betűiből álló szöveget, amelyet egy másik számítógépről kaptunk, nem lehet elolvasni - a monitor képernyőjén valamiféle "abrakadabra" látható. Ez annak a ténynek köszönhető, hogy a számítógépek az orosz nyelv eltérő karakterkódolásait használják.
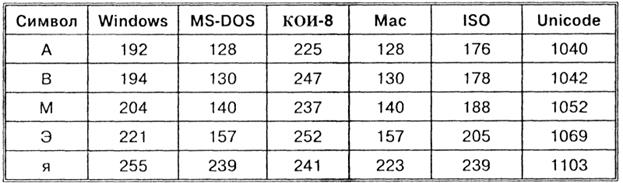
Így minden kódolást saját kódtáblázat határoz meg. A táblázatból látható, hogy ugyanahhoz a bináris kódhoz különböző karakterek vannak hozzárendelve különböző kódolásokban.
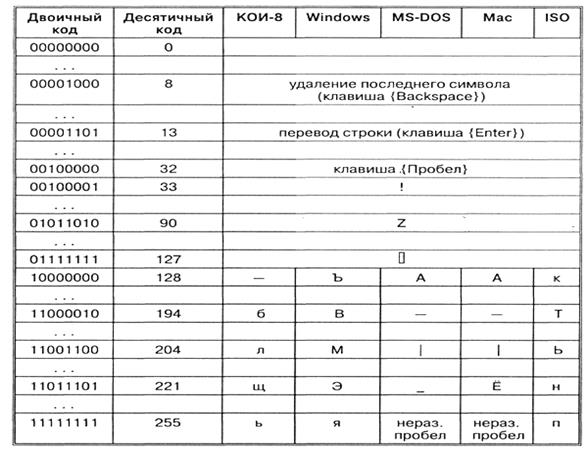 Például a 221, 194, 204 numerikus kódok sorozata a CP1251 kódolásban a "számítógép" szót alkotja, míg más kódolásokban értelmetlen karakterkészlet lesz.
Például a 221, 194, 204 numerikus kódok sorozata a CP1251 kódolásban a "számítógép" szót alkotja, míg más kódolásokban értelmetlen karakterkészlet lesz. Szerencsére a legtöbb esetben a felhasználónak nem kell törődnie a szöveges dokumentumok átkódolásával, ezt ugyanis az alkalmazásokba épített speciális konvertáló programok végzik.
V . A szöveges információ mennyiségének kiszámítása
1. feladat: Kódolja a "Róma" szót a KOI8-R és a CP1251 kódolási táblázatok segítségével.
Megoldás:

2. feladat: Feltételezve, hogy minden karakter egy bájttal van kódolva, becsülje meg a következő mondat információmennyiségét:
"A legőszintébb szabályok nagybátyám,
Amikor komolyan megbetegedtem,
Kényszerítette magát, hogy tisztelje
És nem tudnék jobbat elképzelni."
Megoldás: Ebben a kifejezésben 108 karakter található, beleértve az írásjeleket, idézőjeleket és szóközöket. Ezt a számot megszorozzuk 8 bittel. 108*8=864 bitet kapunk.
3. feladat: A két szöveg ugyanannyi karaktert tartalmaz. Az első szöveg oroszul, a második a Naguri törzs nyelvén íródott, amelynek ábécéje 16 karakterből áll. Kinek a szövege tartalmaz több információt?
Megoldás:
1) I \u003d K * a (a szöveg információmennyisége egyenlő a karakterek számának és egy karakter információs súlyának szorzatával).
2) Mert mindkét szöveg ugyanannyi karakterből áll (K), akkor a különbség az ábécé egy karakterének információtartalmától függ (a).
3) 2 a1 = 32, azaz. a 1 = 5 bit, 2 a2 = 16, azaz. és 2 = 4 bit.
4) I 1 = K * 5 bit, I 2 = K * 4 bit.
5) Ez azt jelenti, hogy az orosz nyelvű szöveg 5/4-szer több információt tartalmaz.
4. feladat: A 2048 karaktert tartalmazó üzenet térfogata 1/512 MB volt. Határozza meg az ábécé erejét!
Megoldás:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 bit - az üzenet információmennyisége bitekre lett konvertálva.
2) a \u003d I / K \u003d 16384 / 1024 \u003d 16 bit - az ábécé egy karakterére esik.
3) 2*16*2048 = 65536 karakter – a használt ábécé ereje.
5. feladat: A Canon LBP lézernyomtató átlagosan 6,3 Kb/s sebességgel nyomtat. Mennyi ideig tart egy 8 oldalas dokumentum kinyomtatása, ha ismert, hogy egy oldalon átlagosan 45 sor van, soronként 70 karakter (1 karakter - 1 bájt)?
Megoldás:
1) Keresse meg az 1 oldalon található információ mennyiségét: 45 * 70 * 8 bit = 25200 bit
2) Keresse meg az információ mennyiségét 8 oldalon: 25200 * 8 = 201600 bit
3) Egységes mértékegységekhez vezetünk. Ehhez az Mbps-t bitekre fordítjuk: 6,3 * 1024 = 6451,2 bps.
4) Keresse meg a nyomtatási időt: 201600: 6451,2 = 31 másodperc.
Bibliográfia
1. Ageev V.M. Információ és kódolás elmélete: mérési információk diszkretizálása és kódolása. - M.: MAI, 1977.
2. Kuzmin I.V., Kedrus V.A. Az információelmélet és a kódolás alapjai. - Kijev, Vishcha iskola, 1986.
3. A szövegtitkosítás legegyszerűbb módszerei / D.M. Zlatopolsky. - M.: Chistye Prudy, 2007 - 32 p.
4. Ugrinovich N.D. Informatika és Információs technológia. Tankönyv 10-11. osztályosoknak / N.D. Ugrinovich. – M.: BINOM. Tudáslaboratórium, 2003. - 512 p.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n