Tabulky kódování dat. Kódování textových informací v počítači
Když vstoupíte textové informace znaky (písmena, čísla, znaky) jsou v počítači kódovány pomocí různých kódových systémů, které se skládají ze sady kódových tabulek umístěných na odpovídajících stránkách norem pro kódování textových informací. V takových tabulkách je každému znaku přiřazen specifický číselný kód v hexadecimálním nebo desítkovém zápisu, tj. kódové tabulky odrážejí shodu mezi obrázky znaků a číselnými kódy a jsou navrženy pro kódování a dekódování textových informací. Při zadávání textových informací pomocí počítačové klávesnice je každý vstupní znak zakódován, tj. převeden na číselný kód, při výstupu textové informace na výstupní zařízení počítače (displej, tiskárna nebo plotr) je jeho obraz vytvořen pomocí číselného kódu znaku. . Přiřazení konkrétního číselného kódu symbolu je výsledkem dohody mezi příslušnými organizacemi v různých zemích. V současné době neexistuje jediná univerzální kódová tabulka, která by vyhovovala písmenům národních abeced různých zemí.
Moderní kódové tabulky obsahují mezinárodní a národní části, to znamená, že obsahují písmena latinské a národní abecedy, čísla, aritmetická a interpunkční znaménka, matematické a řídicí znaky a pseudografické znaky. Mezinárodní část kódové tabulky založená na standardu ASCII (Americký standardní kód pro výměnu informací), zakóduje první polovinu znaků kódové tabulky číselnými kódy od 0 do 7 F16, nebo v desítkové soustavě čísel od 0 do 127. V tomto případě jsou funkčním klávesám (F1, F2, F3 atd.) klávesnice osobního počítače přiřazeny kódy od 0 do 20 16 (0 × 32 10). Na Obr. 3.1 ukazuje mezinárodní část kódových tabulek založených na standardu ASCII. Buňky tabulky jsou číslovány v desítkové a šestnáctkové soustavě čísel.

Obr 3.1. Mezinárodní část tabulky kódů (standard ASCII) s čísly buněk v desítkové (a) a šestnáctkové (b) číselné soustavě
Národní část tabulek kódů obsahuje kódy národních abeced, které se také říká tabulka znakové sady. (znaková sada).
V současné době pro podporu písmen ruské abecedy (cyrilice) existuje několik kódových tabulek (kódování), které používají různé operační systémy, což je značná nevýhoda a v některých případech vede k problémům spojeným s operacemi dekódování číselných hodnot. postav. V tabulce. 3.1 ukazuje názvy kódových stránek (norem), na kterých jsou umístěny tabulky (kódování) azbuky.
Tabulka 3.1
Jedním z prvních standardů pro kódování azbuky na počítačích byl standard KOI8-R. Národní část kódové tabulky této normy je znázorněna na Obr. 3.2.

Rýže. 3.2. Národní část kódové tabulky standardu KOI8-R
V současné době se také používá kódová tabulka umístěná na stránce CP866 standardu kódování textových informací, který se používá v operačním systému MS DOS nebo relace MS DOS pro zakódování azbuky (obr. 3.3, A).


Rýže. 3.3. Národní část kódové tabulky, která se nachází na straně СР866 (a) a na straně СР1251 (b) standardu kódování textových informací
V současné době se pro kódování cyrilice nejrozšířenější kódová tabulka nachází na stránce СР1251 odpovídajícího standardu, který se používá v operačních systémech rodiny Okna firmy Microsoft(obr. 3.2, b). Ve všech prezentovaných kódových tabulkách kromě standardní tabulky unicode, Pro kódování jednoho znaku je přiděleno 8 bitů (8 bitů).
Na konci minulého století se objevil nový mezinárodní standard unicode, ve kterém je jeden znak reprezentován dvoubajtovým binárním kódem. Aplikace tohoto standardu je pokračováním vývoje univerzálního mezinárodního standardu, který umožňuje řešit problém kompatibility kódování národních znaků. Pomocí tohoto standardu můžete zakódovat 2 16 = 65536 různých znaků. Na Obr. 3.4 ukazuje kódovou tabulku 0400 (ruská abeceda) normy Unicode.
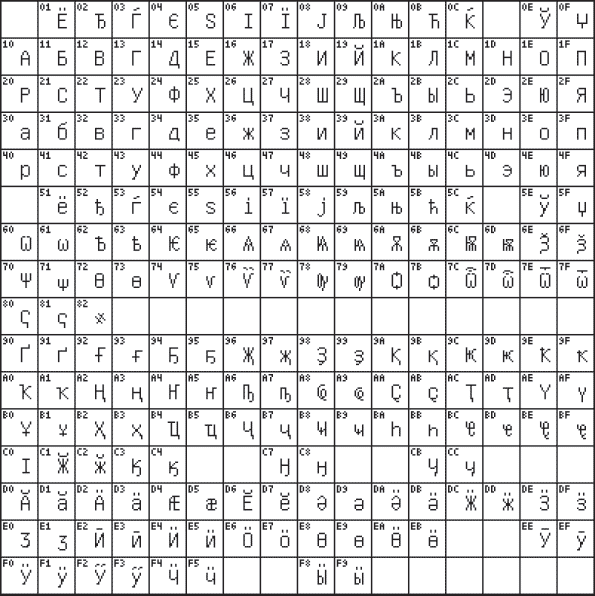
Rýže. 3.4. Tabulka kódů 0400 standardu Unicode
Vysvětleme na příkladu, co bylo řečeno o kódování textových informací.
Příklad 3.1Zakódujte slovo „Počítač“ jako sekvenci desítkových a šestnáctkových čísel pomocí kódování CP1251. Jaké znaky se zobrazí v tabulkách kódů SR866 a KOI8-R při použití přijatého kódu.
Hexadecimální a binární kódové sekvence pro slovo „Počítač“ na základě kódovací tabulky CP1251 (viz obr. 3.3, b) bude vypadat takto:
Tato kódová sekvence v kódováních CP866 a KOI8-R zobrazí následující znaky:
K převodu textových dokumentů v ruském jazyce z jednoho standardu kódování textových informací na jiný se používají speciální programy - převodníky. Převodníky jsou obvykle zabudovány do jiných programů. Příkladem je program prohlížeče - Internet Explorer (IE) který má vestavěný převodník. Program prohlížeče je speciální program pro prohlížení obsahu webové stránky v celosvětové počítačové síti Internet. Použijme tento program k potvrzení výsledku mapování znaků získaného v příkladu 3.1. Chcete-li to provést, proveďte následující kroky.
1. Spusťte Poznámkový blok (Poznámkový blok). Program Poznámkový blok v operačním systému Windows XP se spouští pomocí příkazu: [Tlačítko Start– Programy – Příslušenství – Poznámkový blok]. V okně programu Poznámkový blok, které se otevře, zadejte slovo "Počítač" pomocí syntaxe značkovacího jazyka hypertextových dokumentů - HTML (Hyper Text Markup Language). Tento jazyk se používá k vytváření dokumentů na webu. Text by měl vypadat takto:
Počítač
, kdea
tagy (speciální konstrukce) jazyka HTML pro nadpisy. Na Obr. 3.5 ukazuje výsledek těchto akcí.
Rýže. 3.5. Zobrazte text v okně programu Poznámkový blok
Tento text uložíme provedením příkazu: [Soubor - Uložit jako ...] do příslušné složky v počítači, při ukládání textu dáme souboru název - Poznámka s příponou souboru. html.
2. Spusťte program internet Explorer, provedením příkazu: [Tlačítko Start- programy - Internet Explorer]. Po spuštění programu se zobrazí okno zobrazené na Obr. 3.6
Rýže. 3.6. Okno přístupu offline
Vyberte a aktivujte tlačítko Offline tím se počítač nepřipojí ke globálnímu internetu. Zobrazí se hlavní okno programu Microsoft Internet Explorer, znázorněno na Obr. 3.7.
Rýže. 3.7. Hlavní okno aplikace Microsoft Internet Explorer
Proveďme následující příkaz: [Soubor - Otevřít], objeví se okno (obr. 3.8), ve kterém musíte zadat název souboru a kliknout na tlačítko OK nebo stiskněte tlačítko Přehled… a najděte soubor Note.html.

Rýže. 3.8. Otevřené okno
Hlavní okno programu Internet Explorer bude mít podobu znázorněnou na obr. 3.9. V okně se zobrazí slovo „Počítač“. Dále pomocí horní nabídky programu internet Explorer, spusťte následující příkaz: [View - Encoding - Cyrillic (DOS)]. Po provedení tohoto příkazu v okně programu internet Explorer symboly zobrazené na Obr. 3.10. Při provádění příkazu: [View - Encoding - Cyrillic (KOI8-R)] v okně programu internet Explorer symboly zobrazené na Obr. 3.11.

Rýže. 3.9. Znaky zobrazené s kódováním CP1251
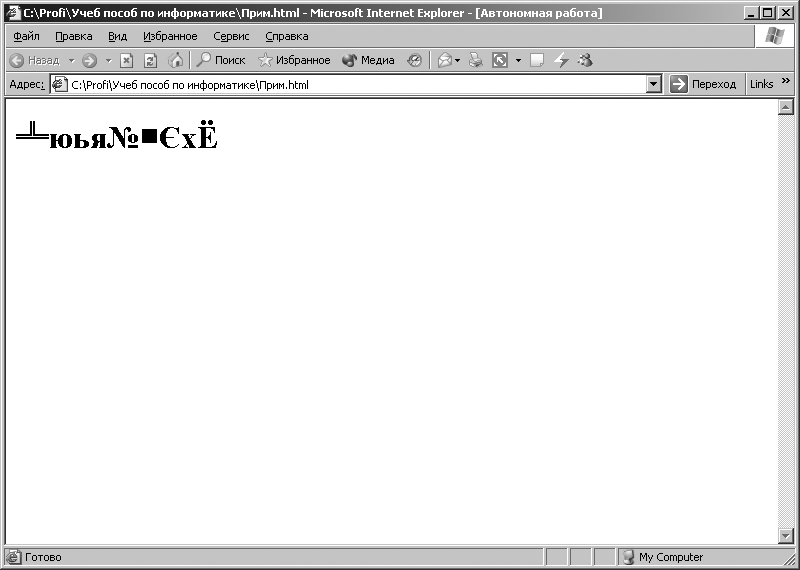
Rýže. 3.10. Znaky zobrazené, když je povoleno kódování CP866 pro sekvenci kódu reprezentovanou v kódování CP1251
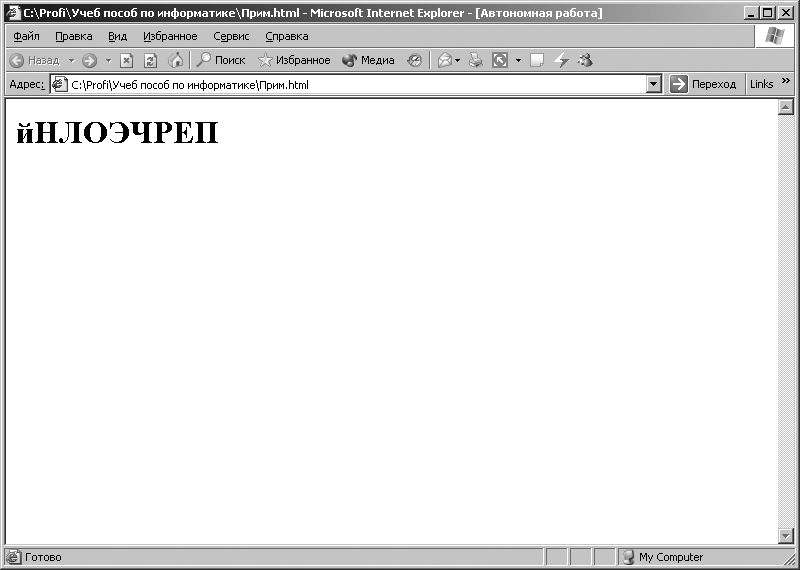
Rýže. 3.11. Znaky zobrazené, když je povoleno kódování KOI8-R pro sekvenci kódů reprezentovanou v kódování CP1251
Takto získané pomocí programu internet Explorer sekvence znaků odpovídají sekvencím znaků získaným pomocí kódových tabulek CP866 a KOI8-R v příkladu 3.1.
3.2. Kódování grafických informací
Grafické informace prezentované ve formě kreseb, fotografií, diapozitivů, pohyblivých obrázků (animace, video), diagramů, kreseb lze vytvářet a upravovat pomocí počítače, přičemž jsou vhodně zakódovány. V současnosti je jich dost velký počet aplikační programy pro zpracování grafických informací, ale všechny implementují tři typy počítačové grafiky: rastrovou, vektorovou a fraktálovou.
Pokud se blíže podíváte na grafický obrázek na obrazovce monitoru počítače, můžete vidět velké množství vícebarevných bodů (pixelů - z angličtiny. pixel, vytvořený z obrazový prvek obrazový prvek), které po sestavení tvoří daný grafický obrázek. Z toho můžeme usoudit: grafický obrázek v počítači je určitým způsobem zakódován a musí být prezentován jako grafický soubor. Soubor je hlavní strukturní jednotkou pro organizaci a ukládání dat v počítači a v tomto případě by měl obsahovat informace o tom, jak prezentovat tuto sadu bodů na obrazovce monitoru.
Soubory vytvořené na základě vektorové grafiky obsahují informace ve formě matematických závislostí (matematické funkce, které popisují lineární závislosti) a související údaje o tom, jak sestrojit obraz objektu pomocí úseček (vektorů) při zobrazení na obrazovce monitoru počítače.
Soubory vytvořené na základě rastrové grafiky předpokládají uložení dat o každém jednotlivém bodě obrázku. Zobrazení rastrové grafiky nevyžaduje složité matematické výpočty, stačí získat údaje o každém bodu obrázku (jeho souřadnice a barvu) a zobrazit je na obrazovce monitoru počítače.
V procesu kódování obrázku se provádí jeho prostorové vzorkování, tj. obrázek je rozdělen do samostatných bodů a každému bodu je přiřazen barevný kód (žlutá, červená, modrá atd.). Pro zakódování každého bodu barevného grafického obrázku se uplatňuje princip rozkladu libovolné barvy na její hlavní složky, které se používají jako tři základní barvy: červená (anglické slovo Červené, označený písmenem NA), zelená (zelená, označený písmenem G), modrý (Modrý, označit buk PROTI). Jakoukoli bodovou barvu vnímanou lidským okem lze získat aditivním (proporcionálním) přidáním (smícháním) tří základních barev – červené, zelené a modré. Tento systém kódování se nazývá barevný systém. RGB. Obrazové soubory, které používají systém barev RGB, představují každý bod obrázku jako trojice barev - tři číselné hodnoty R, G a PROTI, odpovídající intenzitám červené, zelené a modré květy. Proces kódování grafického obrazu se provádí pomocí různých technických prostředků (skener, digitální fotoaparát, digitální videokamera atd.); výsledkem je bitmapový obrázek. Při přehrávání barevných grafických obrázků na obrazovce barevného počítačového monitoru se barva každého bodu (pixelu) takového obrázku získá smícháním tří základních barev. R,G a b.
Kvalitu rastrového obrázku určují dva hlavní parametry – rozlišení (počet horizontálních a vertikálních bodů) a použitá barevná paleta (počet barev určený pro každý bod obrázku). Rozlišení je specifikováno zadáním počtu horizontálních a vertikálních bodů, například 800 x 600 bodů.
Existuje vztah mezi počtem barev přiřazených pixelu rastrového obrázku a množstvím informací, které je třeba alokovat pro uložení barvy pixelu, určený poměrem (vzorec R. Hartleyho):
kde já– množství informací; N- počet barev daný bodu.
Množství informací potřebných k uložení barvy bodu se také nazývá barevná hloubka nebo kvalita barev.
Pokud je tedy počet barev zadaný pro obrazový bod N= 256, pak se množství informací potřebných pro jejich uložení (barevná hloubka) podle vzorce (3.1) bude rovnat já= 8 bitů.
Počítače používají různé grafické režimy zobrazení pro zobrazení grafických informací. Zde je třeba poznamenat, že kromě grafického režimu monitoru existuje také textový režim, ve kterém je obrazovka monitoru konvenčně rozdělena na 25 řádků po 80 znacích na řádek. Tyto grafické režimy se vyznačují rozlišením obrazovky monitoru a kvalitou barev (barevnou hloubkou). Nastavení grafického režimu obrazovky monitoru v operačním systému MS Windows XP musíte provést příkaz: [Tlačítko Start– Nastavení – Ovládací panely – Displej]. V zobrazeném dialogovém okně "Vlastnosti: Zobrazení" (obr. 3.12) vyberte záložku "Parametry" a pomocí posuvníku "Rozlišení obrazovky" vyberte vhodné rozlišení obrazovky (800x600 pixelů, 1024x768 pixelů atd.). Pomocí rozevíracího seznamu "Kvalita barev" můžete vybrat barevnou hloubku - "Nejvyšší (32 bitů)", "Střední (16 bitů)" atd., přičemž počet barev přiřazených každému bodu obrázku bude v daném pořadí rovná se 2 32 (4294967296), 2 16 (65536) atd.

Rýže. 3.12. Dialogové okno Vlastnosti zobrazení
Pro implementaci každého z grafických režimů obrazovky monitoru je vyžadován určitý informační objem video paměti počítače. Požadovaný informační objem video paměti (PROTI) se určí z poměru
kde TO - počet obrazových bodů na obrazovce monitoru (K = AB); A - počet vodorovných bodů na obrazovce monitoru; V - počet vertikálních bodů na obrazovce monitoru; já– množství informací (barevná hloubka).
Pokud má tedy obrazovka monitoru rozlišení 1024 x 768 pixelů a paletu skládající se z 65 536 barev, bude barevná hloubka podle vzorce (3.1) I = log 2 65 538 = 16 bitů, počet pixelů bude být: K = 1024 x 768 = 786432 a požadovaný informační objem video paměti v souladu s (3.2) bude roven
V = 786432 16 bitů = 12582912 bitů = 1572864 bajtů = 1536 KB = 1,5 MB.
Na závěr je třeba poznamenat, že kromě uvedených charakteristik jsou nejdůležitějšími vlastnostmi monitoru geometrické rozměry jeho obrazovky a obrazové body. Geometrické rozměry obrazovky jsou dány velikostí úhlopříčky monitoru. Úhlopříčka monitorů se udává v palcích (1 palec = 1" = 25,4 mm) a může nabývat hodnot rovnající se: 14", 15", 17", 21" atd. Moderní technologie výroby monitorů dokážou zajistit velikost bodu obrazu rovný 0,22 mm.
Pro každý monitor tedy existuje fyzicky maximální možné rozlišení obrazovky, určené velikostí jeho úhlopříčky a velikostí obrazového bodu.
Cvičení pro seberealizaci
1. Použití programu MS Excel převést tabulky kódů ASCII, СР866, СР1251, KOI8-R na tabulky ve tvaru: do buněk prvního sloupce tabulek pište v abecedním pořadí velká a poté malá písmena latinky a azbuky, do buněk druhého sloupce - kódy odpovídající písmenům v desítkové soustavě, v buňkách třetí sloupec - kódy odpovídající písmenům v šestnáctkové soustavě. Hodnoty kódu musí být vybrány z odpovídajících kódových tabulek.
2. Zakódujte a zapište následující slova jako posloupnost čísel v desítkové a šestnáctkové soustavě:
A) internet Explorer, b) Microsoft Office proti) CorelDRAW.
Produkujte kódováním pomocí aktualizované kódovací tabulky ASCII získané v předchozím cvičení.
3. Dekódujte pomocí vylepšené kódovací tabulky KOI8-R sekvence čísel zapsaných v hexadecimálním číselném systému:
a) FC CB DA C9 D3 D4 C5 CE C3 C9 D1;
b) EB CF CE C6 CF D2 CD C9 DA CD;
c) FC CB D3 D0 D2 C5 D3 C9 CF CE C9 DA CD.
4. Jak bude vypadat slovo „Kybernetika“ zapsané v kódování CP1251 při použití kódování CP866 a KOI8-R? Zkontrolujte výsledky pomocí programu Internet Explorer.
5. Pomocí tabulky kódů na Obr. 3.1 A, dekódujte následující kódové sekvence zapsané v binární notaci:
a) 01010111 01101111 01110010 01100100;
b) 01000101 01111000 01100011 01100101 01101100;
c) 01000001 01100011 01100011 01100101 01110011 01110011.
6. Určete informační objem slova „Economy“ zakódovaného pomocí kódových tabulek СР866, СР1251, Unicode a KOI8-R.
7. Určete informační objem souboru získaného skenováním barevného obrázku 12x12 cm.Rozlišení skeneru použitého ke skenování tohoto obrázku je 600 dpi. Skener nastaví barevnou hloubku bodu obrázku na 16 bitů.
Rozlišení skeneru 600 dpi (bodový palec - bodů na palec) určuje schopnost skeneru s tímto rozlišením rozlišit 600 bodů na 1palcovém segmentu.
8. Určete informační objem souboru získaného skenováním barevného obrázku o velikosti A4. Rozlišení skeneru použitého ke skenování tohoto obrázku je 1200 dpi. Skener nastaví barevnou hloubku bodu obrázku na 24 bitů.
9. Určete počet barev v paletě při barevné hloubce 8, 16, 24 a 32 bitů.
10. Určete požadované množství video paměti pro grafické režimy obrazovky monitoru 640 x 480, 800 x 600, 1024 x 768 a 1280 x 1024 pixelů s barevnou hloubkou obrazového bodu 8, 16, 24 a 32 bitů. Výsledky jsou shrnuty v tabulce. Vyvinout se v MS Excel program pro automatizaci výpočtů.
11. Určete maximální počet barev, které lze použít k uložení obrázku o velikosti 32 x 32 pixelů, pokud má počítač pro obrázek přiděleno 2 KB paměti.
12. Určete maximální možné rozlišení obrazovky monitoru s úhlopříčkou 15" a velikostí bodu obrazu 0,28 mm.
13. Jaké grafické režimy provozu monitoru může zajistit 64 MB videopaměti?
Materiál pro samostudium na téma Přednáška 2
Kódování ASCII
Tabulka kódování ASCII (ASCII - American Standard Code for Information Interchange - American Standard Code for Information Interchange).
Celkem lze pomocí tabulky kódování ASCII (obrázek 1) zakódovat 256 různých znaků. Tato tabulka je rozdělena na dvě části: hlavní (s kódy od OOh do 7Fh) a doplňkovou (od 80h do FFh, kde písmeno h označuje, že kód patří do hexadecimální číselné soustavy).
Obrázek 1
Pro zakódování jednoho znaku z tabulky je přiděleno 8 bitů (1 byte). Při zpracování textových informací může jeden bajt obsahovat kód nějakého znaku – písmena, číslice, interpunkční znaménka, akční znaménka atd. Každý znak má svůj vlastní kód ve formě celého čísla. V tomto případě jsou všechny kódy shromažďovány ve speciálních tabulkách, nazývaných kódovací tabulky. S jejich pomocí se znakový kód převede na jeho viditelnou reprezentaci na obrazovce monitoru. Výsledkem je, že jakýkoli text v paměti počítače je reprezentován jako sekvence bajtů s kódy znaků.
Například slovo ahoj! bude kódováno následovně (Tabulka 1).
stůl 1
|
Binární kód | ||||||
|
Kód desítkové |
Obrázek 1 ukazuje znaky obsažené ve standardním (anglickém) a rozšířeném (ruském) kódování ASCII.
První polovina ASCII tabulky je standardizovaná. Obsahuje kontrolní kódy (od 00h do 20h a 77h). Tyto kódy byly z tabulky odstraněny, protože se nevztahují na textové prvky. Jsou zde také umístěny interpunkční znaménka a matematická znaménka: 2lh - !, 26h - &, 28h - (, 2Bh -+, ..., velká a malá latinská písmena: 41h - A, 61h - a.
Druhá polovina tabulky obsahuje národní písma, pseudografické symboly, ze kterých lze sestavovat tabulky, speciální matematické symboly. Spodní část kódovací tabulky lze vyměnit pomocí příslušných ovladačů - ovládacích pomocných programů. Tato technika umožňuje používat více písem a jejich řezů.
Displej pro každý znakový kód by měl zobrazovat obrázek znaku – nejen digitální kód, ale i obrázek, který mu odpovídá, protože každý znak má svůj vlastní tvar. Popis tvaru každého znaku je uložen ve speciální paměti displeje - generátoru znaků. Například zvýraznění znaku na obrazovce IBM PC se provádí pomocí bodů, které tvoří matici znaků. Každý pixel v takové matici je prvek obrazu a může být světlý nebo tmavý. Tmavý bod je zakódován číslem 0, světlý (světlý) číslem 1. Pokud jsou tmavé pixely reprezentovány tečkou v maticovém poli znaku a světlé pixely hvězdičkou, můžete tvar graficky znázornit symbolu.
Lidé rozdílné země používat symboly k psaní slov jejich rodných jazyků. V dnešní době je většina aplikací, včetně e-mailových systémů a webových prohlížečů, čistě 8bitových, což znamená, že mohou zobrazovat a správně číst pouze 8bitové znaky podle standardu ISO-8859-1.
Na světě je přes 256 znaků (včetně azbuky, arabštiny, čínštiny, japonštiny, korejštiny a thajštiny) a přibývají další a další znaky. A to vytváří pro mnoho uživatelů následující mezery:
Ve stejném dokumentu není možné použít znaky z různých sad kódování. Vzhledem k tomu, že každý textový dokument používá svou vlastní sadu kódování, jsou s automatickým rozpoznáváním textu velké potíže.
Objevují se nové symboly (například: Euro), v důsledku čehož ISO vyvíjí nový standard ISO-8859-15, který je velmi podobný ISO-8859-1. Rozdíl je následující: symboly pro označení starých měn, které se v současnosti nepoužívají, byly odstraněny z kódovací tabulky starého standardu ISO-8859-1, aby se uvolnilo místo pro nově se objevující symboly (např. euro). Díky tomu mohou mít uživatelé na svých discích stejné dokumenty, ale v jiném kódování. Řešením těchto problémů je přijetí jediné mezinárodní sady kódování, která se nazývá univerzální kódování nebo Unicode.
Kódování Unicode
Standard byl navržen v roce 1991 neziskovou organizací Unicode Consortium (anglicky Unicode Consortium, Unicode Inc.). Použití tohoto standardu umožňuje kódovat velmi velké množství znaků z různých písem: čínské znaky, matematické symboly, písmena řecké abecedy, latinky a azbuky mohou koexistovat v dokumentech Unicode, zatímco přepínání kódových stránek se stává zbytečným.
Standard se skládá ze dvou hlavních částí: univerzální znakové sady (UCS, univerzální znaková sada) a rodiny kódování (UTF, transformační formát Unicode). Univerzální znaková sada specifikuje vzájemnou shodu znaků s kódy - prvky kódového prostoru představující nezáporná celá čísla. Rodina kódování definuje strojovou reprezentaci sekvence kódů UCS.
Standard Unicode byl vyvinut s cílem vytvořit jediné kódování znaků pro všechny moderní a mnoho starověkých psaných jazyků. Každý znak v tomto standardu je kódován 16 bity, což mu umožňuje pokrýt nesrovnatelně větší počet znaků než dříve akceptovaná 8bitová kódování. Dalším důležitým rozdílem mezi Unicode a jinými kódovacími systémy je to, že nejen přiřazuje jedinečný kód každému znaku, ale také definuje různé vlastnosti tohoto znaku, například:
typ znaku (velké písmeno, malé písmeno, číslo, interpunkční znaménko atd.);
atributy znaků (zobrazení zleva doprava nebo zprava doleva, mezera, zalomení řádku atd.);
odpovídající velké nebo malé písmeno (pro malá a velká písmena);
odpovídající číselnou hodnotu (pro číselné znaky).
Celý rozsah kódů od 0 do FFFF je rozdělen do několika standardních podmnožin, z nichž každá odpovídá buď abecedě některého jazyka, nebo skupině speciálních znaků, které jsou svými funkcemi podobné. Níže uvedený diagram obsahuje obecný seznam podmnožin Unicode 3.0 (obrázek 2).

Obrázek 2
Standard Unicode je základem pro ukládání a text v mnoha moderních počítačových systémech. Není však kompatibilní s většinou internetových protokolů, protože jeho kódy mohou obsahovat libovolnou hodnotu bajtu a protokoly obvykle používají bajty 00 - 1F a FE - FF jako servisní bajty. Pro dosažení kompatibility bylo vyvinuto několik transformačních formátů Unicode (UTF, Unicode Transformation Formats), z nichž UTF-8 je dnes nejběžnější. Tento formát definuje následující pravidla pro převod každého kódu Unicode na sadu bajtů (od jednoho do tří) vhodných pro přenos pomocí internetových protokolů.
Zde x,y,z označují bity zdrojového kódu, které je třeba extrahovat, počínaje nejméně významným, a zadávat do bajtů výsledku zprava doleva, dokud nejsou zaplněny všechny určené pozice.
Další vývoj standardu Unicode je spojen s přidáváním nových jazykových rovin, tzn. znaků v rozsahu 10000 - 1FFFF, 20000 - 2FFFF atd., kde má obsahovat kódování pro skripty mrtvých jazyků, které nejsou zahrnuty v tabulce výše. Pro kódování těchto dalších znaků byl vyvinut nový formát UTF-16.
Existují tedy 4 hlavní způsoby kódování bajtů ve formátu Unicode:
UTF-8: 128 znaků kódovaných v jednom bajtu (formát ASCII), 1920 znaků kódovaných ve 2 bajtech ((římština, řečtina, azbuka, koptština, arménština, hebrejština, arabské znaky), 63488 znaků kódovaných ve 3 bajtech (čínština, japonština atd.) .) Zbývajících 2 147 418 112 znaků (zatím nepoužitých) lze zakódovat 4, 5 nebo 6 bajty.
UCS-2: Každý znak je reprezentován 2 bajty. Toto kódování obsahuje pouze prvních 65 535 znaků z formátu Unicode.
UTF-16: Toto je rozšíření UCS-2 a obsahuje 1 114 112 znaků Unicode. Prvních 65 535 znaků představuje 2 bajty, zbytek 4 bajty.
USC-4: Každý znak je zakódován 4 bajty.
Kódování textových informací
Pojďme se podívat na některá fakta, která víme:
Sada symbolů používaných k psaní textu se nazýváabecedně.
Počet znaků v abecedě jeNapájení.
Vzorec pro určení množství informací:N=2b,
kde N je mocnina abecedy (počet znaků),
b - počet bitů (informační váha symbolu).
Téměř všechny potřebné znaky lze umístit do abecedy s kapacitou 256 znaků. Tato abeceda se nazývádostatečný.
Protože 256 = 28 , pak je váha 1 znaku 8 bitů.
8bitová měrná jednotka dostala název1 bajt:
1 bajt = 8 bitů.
Binární kód každého znaku v počítačovém textu zabírá 1 bajt paměti.
Jak jsou textové informace reprezentovány v paměti počítače?
|
| Texty se zadávají do paměti počítače pomocí klávesnice. Klávesy jsou psány nám známými písmeny, číslicemi, interpunkčními znaménky a dalšími symboly. Zadávají RAM v binárním kódu. To znamená, že každý znak je reprezentován 8bitovým binárním kódem. Kódování spočívá v tom, že každému znaku je přiřazen jedinečný dekadický kód od 0 do 255 nebo odpovídající binární kód od 00000000 do 11111111. Člověk tedy rozlišuje znaky podle stylu a počítač podle kódu. |

Pohodlí kódování znaků po bajtech je zřejmé, protože bajt je nejmenší adresovatelná část paměti, a proto může procesor při zpracování textu přistupovat ke každému znaku samostatně. Na druhou stranu, 256 znaků je docela dost na to, aby reprezentovalo širokou škálu informací o znacích.
Nyní vyvstává otázka, který osmibitový binární kód vložit do korespondence s každým znakem.
Je jasné, že jde o podmíněnou záležitost, můžete přijít na mnoho způsobů kódování.
Všechny symboly počítačové abecedy jsou číslovány od 0 do 255. Každému číslu odpovídá osmimístný binární kód od 00000000 do 11111111. Tento kód je jednoduše pořadové číslo znaku v binární číselné soustavě.
Tabulka, ve které jsou všem znakům počítačové abecedy přiřazena pořadová čísla, se nazývá kódovací tabulka.
Pro odlišné typy Počítač používá různé kódovací tabulky.
Stůl se stal mezinárodním standardem pro PC.ASCII(vyslovuje se asci) (Americký standardní kód pro výměnu informací).
Tabulka ASCII kódů je rozdělena na dvě části.
Mezinárodním standardem je pouze první polovina tabulky, tzn. znaky s čísly od0 (00000000), až127 (01111111).
Struktura tabulky ASCII kódování
| Sériové číslo | Kód | Symbol |
| 0 - 31 | 00000000 - 00011111 | Znaky s čísly od 0 do 31 se nazývají řídicí znaky. |
| 32 - 127 | 00100000 - 01111111 | Standardní část tabulky (anglicky). To zahrnuje malá a velká písmena latinské abecedy, desetinné číslice, interpunkční znaménka, všechny druhy hranatých závorek, obchodní a jiné symboly. |
| 128 - 255 | 10000000 - 11111111 | Alternativní část tabulky (ruština). |
První polovina tabulky kódů ASCII
|
|

Upozorňuji na skutečnost, že v tabulce kódování jsou písmena (velká a malá písmena) uspořádána v abecedním pořadí a čísla jsou seřazeny vzestupně podle hodnot. Toto dodržování lexikografického řádu v uspořádání znaků se nazývá princip sekvenčního kódování abecedy.
U písmen ruské abecedy je také dodržován princip sekvenčního kódování.
Druhá polovina tabulky kódů ASCII

Bohužel v současné době existuje pět různých kódování azbuky (KOI8-R, Windows, MS-DOS, Macintosh a ISO). Z tohoto důvodu často vznikají problémy s přenosem ruského textu z jednoho počítače do druhého, z jednoho softwarového systému do druhého.
Chronologicky byl jedním z prvních standardů pro kódování ruských písmen na počítačích KOI8 ("Information Exchange Code, 8-bit"). Toto kódování se používalo již v 70. letech na počítačích řady počítačů EC a od poloviny 80. let se začalo používat v prvních rusifikovaných verzích operačního systému UNIX.
Od začátku 90. let, doby dominance operačního systému MS DOS, zůstává kódování CP866 ("CP" znamená "Code Page", "code page").
Počítače Apple s operačním systémem Mac OS používají vlastní kódování Mac.
Kromě toho Mezinárodní organizace pro normalizaci (International Standards Organization, ISO) schválila další kódování nazvané ISO 8859-5 jako standard pro ruský jazyk.
Nejběžnějším aktuálně používaným kódováním je Microsoft Windows, zkráceně CP1251.
Od konce 90. let byl problém standardizace kódování znaků řešen zavedením nového mezinárodního standardu, tzv.Unicode. Jedná se o 16bitové kódování, tzn. má 2 bajty paměti na znak. V tomto případě se samozřejmě množství obsazené paměti zvýší dvakrát. Ale taková kódová tabulka umožňuje zahrnutí až 65536 znaků. Kompletní specifikace standardu Unicode zahrnuje všechny existující, zaniklé a uměle vytvořené abecedy světa a také mnoho matematických, hudebních, chemických a dalších symbolů.
Zkusme si pomocí ASCII tabulky představit, jak budou slova vypadat v paměti počítače.
Vnitřní reprezentace slov v paměti počítače
| Slova | Paměť |
| soubor | 01100110 01101001 01101100 01100101 |
| disk | 01100100 01101001 01110011 01101011 |
Někdy se stává, že text, který se skládá z písmen ruské abecedy, přijatý z jiného počítače, nelze přečíst - na obrazovce monitoru je vidět nějaký druh "abracadabra". To je způsobeno skutečností, že počítače používají různá kódování znaků ruského jazyka.
Obsah
I. Historie kódování informací………………………………..3
II. Kódovací informace ………………………………………………… 4
III. Kódování textových informací………………………………….4
IV. Typy kódovacích tabulek………………………………………………………...6
V. Výpočet množství textových informací………………………14
Seznam použité literatury………………………………………..16
já . Historie kódování informací
Lidstvo používá šifrování textu (kódování) od okamžiku, kdy se objevily první tajné informace. Zde je několik technik kódování textu, které byly vynalezeny v různých fázích vývoje lidského myšlení:
Kryptografie je kryptografie, systém měnícího se písma, aby byl text pro nezasvěcené osoby nesrozumitelný;
Morseova abeceda nebo nejednotný telegrafní kód, ve kterém je každé písmeno nebo znak reprezentován vlastní kombinací krátkých základních balíčků elektrický proud(tečky) a elementární parcely trojitého trvání (čárky);
 znakový jazyk je znakový jazyk používaný lidmi se sluchovým postižením.
znakový jazyk je znakový jazyk používaný lidmi se sluchovým postižením. Jeden z úplně prvních známé metodyšifrování nese jméno římského císaře Julia Caesara (I. století před naším letopočtem). Tato metoda je založena na nahrazení každého písmena zašifrovaného textu jiným tak, že se abeceda od původního písmene posune o pevný počet znaků a abeceda se čte v kruhu, tedy za písmenem i se uvažuje a. Takže slovo "byte" při posunutí o dva znaky doprava je zakódováno slovem "gvlf". Opačným procesem dešifrování daného slova je nahrazení každého zašifrovaného písmene druhým nalevo od něj.
II. Kódování informací
Kód je soubor konvencí (nebo signálů) pro záznam (nebo přenos) některých předem definovaných konceptů.
Kódování informací je proces vytváření určité reprezentace informace. V užším slova smyslu je pojem „kódování“ často chápán jako přechod od jedné formy prezentace informace k jiné, vhodnější pro ukládání, přenos nebo zpracování.
Obvykle je každý obrázek, když je zakódován (někdy se říká - zašifrovaný), reprezentován samostatným znakem.
Znak je prvkem konečného souboru odlišných prvků.
V užším slova smyslu je pojem „kódování“ často chápán jako přechod od jedné formy prezentace informace k jiné, vhodnější pro ukládání, přenos nebo zpracování.
Počítač umí zpracovávat textové informace. Při zadávání do počítače je každé písmeno zakódováno určitým číslem a při výstupu na externí zařízení (obrazovka nebo tisk) se pro lidské vnímání vytvářejí obrázky písmen pomocí těchto čísel. Korespondence mezi sadou písmen a čísel se nazývá kódování znaků.
Všechna čísla v počítači jsou zpravidla reprezentována nulami a jedničkami (a nikoli deseti číslicemi, jak je u lidí zvykem). Jinými slovy, počítače obvykle pracují v binárním systému, protože zařízení pro jejich zpracování jsou mnohem jednodušší. Zadávání čísel do počítače a jejich výstup pro čtení člověkem lze provádět v obvyklém desítkovém tvaru a všechny potřebné převody provádějí programy běžící na počítači.
III. Kódování textových informací
Stejné informace mohou být prezentovány (zakódovány) v několika formách. S příchodem počítačů bylo nutné zakódovat všechny typy informací, kterými se jednotlivec i lidstvo jako celek zabývá. Ale lidstvo začalo řešit problém kódování informací dávno před příchodem počítačů. Grandiózní výdobytky lidstva – psaní a aritmetika – nejsou ničím jiným než systémem kódování řeči a číselných informací. Informace se nikdy neobjevují ve své čisté podobě, vždy jsou nějakým způsobem prezentovány, nějakým způsobem zakódovány.
Binární kódování je jedním z nejběžnějších způsobů reprezentace informací. V počítačích, robotech a obráběcích strojích s numerickým řízením jsou zpravidla všechny informace, se kterými zařízení pracuje, zakódovány ve formě slov binární abecedy.
Od konce 60. let jsou počítače stále více využívány ke zpracování textových informací a v současnosti zaujímá hlavní podíl osobních počítačů ve světě (a většinu času) zpracování textových informací. Všechny tyto typy informací v počítači jsou reprezentovány binárním kódem, tj. používá se abeceda s mocninou dvou (pouze dva znaky 0 a 1). To je způsobeno tím, že je vhodné reprezentovat informace ve formě sekvence elektrických impulzů: neexistuje žádný impulz (0), existuje impulz (1).
Takové kódování se obvykle nazývá binární a samotné logické sekvence nul a jedniček se nazývají strojový jazyk.
Z pohledu počítače se text skládá z jednotlivých znaků. Znaky zahrnují nejen písmena (velká nebo malá písmena, latinka nebo ruština), ale také číslice, interpunkční znaménka, speciální znaky jako "=", "(", "&" atd.) a dokonce (věnujte zvláštní pozornost!) mezery mezi slovy .
Texty se zadávají do paměti počítače pomocí klávesnice. Klávesy jsou psány nám známými písmeny, číslicemi, interpunkčními znaménky a dalšími symboly. Zadávají RAM v binárním kódu. To znamená, že každý znak je reprezentován 8bitovým binárním kódem.
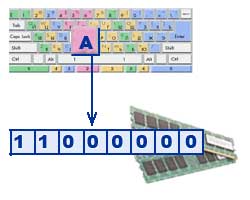 Tradičně se pro zakódování jednoho znaku používá množství informací rovné 1 bajtu, tj. I \u003d 1 byte \u003d 8 bitů. Pomocí vzorce, který dává do souvislosti počet možných událostí K a množství informací I, můžete vypočítat, kolik různých znaků lze zakódovat (za předpokladu, že znaky jsou možné události): K = 2 I = 2 8 = 256, tj. reprezentaci textových informací, můžete použít abecedu s kapacitou 256 znaků.
Tradičně se pro zakódování jednoho znaku používá množství informací rovné 1 bajtu, tj. I \u003d 1 byte \u003d 8 bitů. Pomocí vzorce, který dává do souvislosti počet možných událostí K a množství informací I, můžete vypočítat, kolik různých znaků lze zakódovat (za předpokladu, že znaky jsou možné události): K = 2 I = 2 8 = 256, tj. reprezentaci textových informací, můžete použít abecedu s kapacitou 256 znaků. Tento počet znaků je dostatečný pro reprezentaci textových informací, včetně velkých a malých písmen ruské a latinské abecedy, čísel, znaků, grafických symbolů atd.
Kódování spočívá v tom, že každému znaku je přiřazen jedinečný dekadický kód od 0 do 255 nebo odpovídající binární kód od 00000000 do 11111111. Člověk tedy rozlišuje znaky podle stylu a počítač podle kódu.
Pohodlí kódování znaků po bajtech je zřejmé, protože bajt je nejmenší adresovatelná část paměti, a proto může procesor při zpracování textu přistupovat ke každému znaku samostatně. Na druhou stranu, 256 znaků je docela dost na to, aby reprezentovalo širokou škálu informací o znacích.
V procesu zobrazení znaku na obrazovce počítače se provádí opačný proces - dekódování, tedy převedení znakového kódu na jeho obraz. Je důležité, aby přiřazení konkrétního kódu k symbolu bylo věcí dohody, která je pevně stanovena v tabulce kódů.
Nyní vyvstává otázka, který osmibitový binární kód vložit do korespondence s každým znakem. Je jasné, že jde o podmíněnou záležitost, můžete přijít na mnoho způsobů kódování.
Všechny symboly počítačové abecedy jsou číslovány od 0 do 255. Každému číslu odpovídá osmimístný binární kód od 00000000 do 11111111. Tento kód je jednoduše pořadové číslo znaku v binární číselné soustavě.
IV . Typy kódovacích tabulek
Tabulka, ve které jsou všem znakům počítačové abecedy přiřazena pořadová čísla, se nazývá kódovací tabulka.
Pro různé typy počítačů se používají různé kódovací tabulky.
Jako mezinárodní standard je přijata kódová tabulka ASCII (American Standard Code for Information Interchange), která kóduje první polovinu znaků číselnými kódy od 0 do 127 (kódy od 0 do 32 nejsou přiřazeny znakům, ale funkčním klávesám).
Tabulka ASCII kódů je rozdělena na dvě části.
Mezinárodním standardem je pouze první polovina tabulky, tzn. znaky s čísly od 0 (00000000) do 127 (01111111).
Struktura kódovací tabulky ASCII
| Sériové číslo | Kód | Symbol |
| 0 - 31 | 00000000 - 00011111 | Znaky s čísly od 0 do 31 se nazývají řídicí znaky. Jejich funkcí je řídit proces zobrazování textu na obrazovce nebo tisku, vydávání zvukového signálu, označování textu atd. |
| 32 - 127 | 0100000 - 01111111 | Standardní část tabulky (anglicky). To zahrnuje malá a velká písmena latinské abecedy, desetinné číslice, interpunkční znaménka, všechny druhy hranatých závorek, obchodní a jiné symboly. Znak 32 je mezera, tzn. prázdné místo v textu. Vše ostatní se odráží v určitých znameních. |
| 128 - 255 | 10000000 - 11111111 | Alternativní část tabulky (ruština). Druhá polovina tabulky kódů ASCII, nazývaná kódová stránka (128 kódů počínaje 10000000 a končící 11111111), může mít různé možnosti, každá možnost má své vlastní číslo. Kódová stránka se primárně používá k umístění jiných národních písem než latinky. V ruském národním kódování jsou v této části tabulky umístěny znaky ruské abecedy. |

První polovina tabulky kódů ASCII
Upozorňujeme na skutečnost, že v tabulce kódování jsou písmena (velká a malá písmena) uspořádána v abecedním pořadí a čísla jsou seřazeny vzestupně. Toto dodržování lexikografického řádu v uspořádání znaků se nazývá princip sekvenčního kódování abecedy.
U písmen ruské abecedy je také dodržován princip sekvenčního kódování.
Druhá polovina tabulky kódů ASCII
Bohužel v současné době existuje pět různých kódování azbuky (KOI8-R, Windows, MS-DOS, Macintosh a ISO). Z tohoto důvodu často vznikají problémy s přenosem ruského textu z jednoho počítače do druhého, z jednoho softwarového systému do druhého.
Chronologicky byl jedním z prvních standardů pro kódování ruských písmen na počítačích KOI8 ("Information Exchange Code, 8-bit"). Toto kódování se používalo již v 70. letech na počítačích řady počítačů EC a od poloviny 80. let se začalo používat v prvních rusifikovaných verzích operačního systému UNIX.
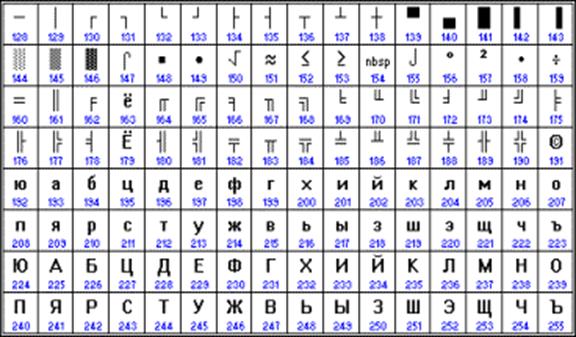
Od začátku 90. let, doby dominance operačního systému MS DOS, zůstává kódování CP866 ("CP" znamená "Code Page", "code page").
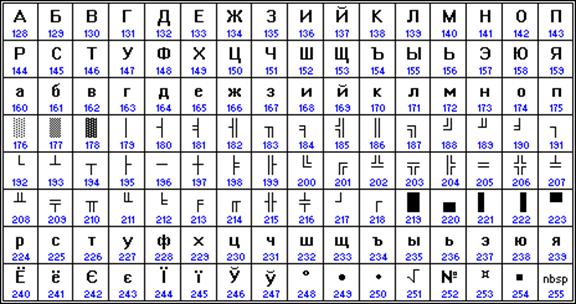
Počítače Apple s operačním systémem Mac OS používají vlastní kódování Mac.

Kromě toho Mezinárodní organizace pro normalizaci (International Standards Organization, ISO) schválila další kódování nazvané ISO 8859-5 jako standard pro ruský jazyk.

Nejběžnějším aktuálně používaným kódováním je Microsoft Windows, zkráceně CP1251. Představený společností Microsoft; vzhledem k široké distribuci operačních systémů (OS) a dalších softwarových produktů této společnosti v Ruská Federace se to rozšířilo.
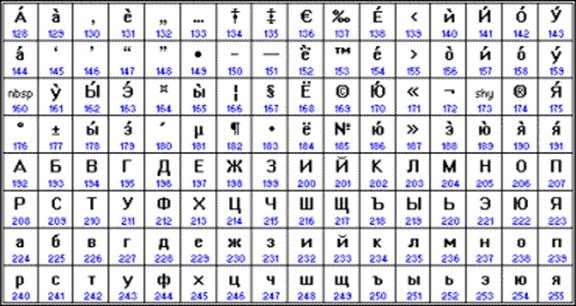
Od konce 90. let byl problém standardizace kódování znaků řešen zavedením nového mezinárodního standardu nazvaného Unicode.

Jedná se o 16bitové kódování, tzn. má 2 bajty paměti na znak. V tomto případě se samozřejmě množství obsazené paměti zvýší dvakrát. Ale taková kódová tabulka umožňuje zahrnutí až 65536 znaků. Kompletní specifikace standardu Unicode zahrnuje všechny existující, zaniklé a uměle vytvořené abecedy světa a také mnoho matematických, hudebních, chemických a dalších symbolů.
Vnitřní reprezentace slov v paměti počítače
pomocí ASCII tabulky
Někdy se stává, že text, který se skládá z písmen ruské abecedy, přijatý z jiného počítače, nelze přečíst - na obrazovce monitoru je vidět nějaký druh "abracadabra". To je způsobeno skutečností, že počítače používají různá kódování znaků ruského jazyka.
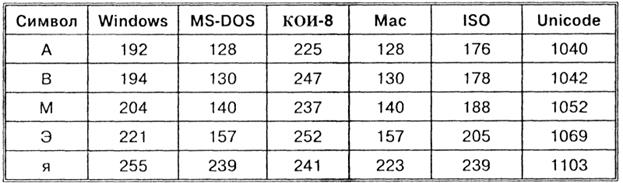
Každé kódování je tedy specifikováno vlastní tabulkou kódů. Jak je vidět z tabulky, stejnému binárnímu kódu jsou přiřazeny různé znaky v různých kódováních.
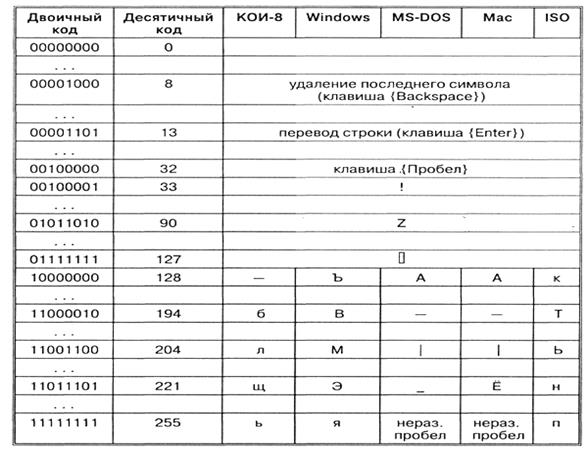 Například sekvence číselných kódů 221, 194, 204 v kódování CP1251 tvoří slovo „počítač“, zatímco v jiných kódováních se bude jednat o nesmyslnou sadu znaků.
Například sekvence číselných kódů 221, 194, 204 v kódování CP1251 tvoří slovo „počítač“, zatímco v jiných kódováních se bude jednat o nesmyslnou sadu znaků. Naštěstí se ve většině případů uživatel nemusí starat o překódování textových dokumentů, protože to zajišťují speciální převodní programy zabudované v aplikacích.
PROTI . Výpočet množství textových informací
Úkol 1: Kódujte slovo „Řím“ pomocí kódovacích tabulek KOI8-R a CP1251.
Řešení:

Úkol 2: Za předpokladu, že každý znak je zakódován jedním bajtem, odhadněte objem informací následující věty:
"Můj strýc nejčestnějších pravidel,
Když jsem vážně onemocněl,
Přinutil se respektovat
A lepší mě nenapadl."
Řešení: Tato fráze obsahuje 108 znaků, včetně interpunkčních znamének, uvozovek a mezer. Toto číslo vynásobíme 8 bity. Dostaneme 108*8=864 bitů.
Úkol 3: Oba texty obsahují stejný počet znaků. První text je napsán v ruštině a druhý v jazyce kmene Naguri, jehož abeceda se skládá ze 16 znaků. Čí text obsahuje více informací?
Řešení:
1) I \u003d K * a (informační objem textu se rovná součinu počtu znaků a informační váhy jednoho znaku).
2) Protože oba texty mají stejný počet znaků (K), pak rozdíl závisí na informačním obsahu jednoho znaku abecedy (a).
3) 2 a1 = 32, tzn. a 1 = 5 bitů, 2 a2 = 16, tzn. a 2 = 4 bity.
4) I 1 = K * 5 bitů, I 2 = K * 4 bity.
5) Znamená to, že text psaný v ruštině nese 5/4krát více informací.
Úkol 4: Objem zprávy obsahující 2048 znaků byl 1/512 MB. Určete sílu abecedy.
Řešení:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 bitů - informační objem zprávy byl převeden na bity.
2) a \u003d I / K \u003d 16384 / 1024 \u003d 16 bitů - připadá na jeden znak abecedy.
3) 2*16*2048 = 65536 znaků - síla použité abecedy.
Úkol 5: Laserová tiskárna Canon LBP tiskne průměrnou rychlostí 6,3 Kbps. Jak dlouho bude trvat tisk 8stránkového dokumentu, pokud je známo, že na jedné stránce je průměrně 45 řádků, 70 znaků na řádek (1 znak - 1 bajt)?
Řešení:
1) Najděte množství informací obsažených na 1 stránce: 45 * 70 * 8 bitů = 25200 bitů
2) Najděte množství informací na 8 stránkách: 25200 * 8 = 201600 bitů
3) Dovedeme k jednotným měrným jednotkám. Za tímto účelem převádíme Mbps na bity: 6,3 * 1024 = 6451,2 bps.
4) Najděte čas tisku: 201600: 6451,2 = 31 sekund.
Bibliografie
1. Ageev V.M. Teorie informace a kódování: diskretizace a kódování měřené informace. - M.: MAI, 1977.
2. Kuzmin I.V., Kedrus V.A. Základy teorie informace a kódování. - Kyjev, škola Vishcha, 1986.
3. Nejjednodušší metody šifrování textu / D.M. Zlatopolský. - M.: Chistye Prudy, 2007 - 32 s.
4. Ugrinovič N.D. Informatika a Informační technologie. Učebnice pro ročníky 10-11 / N.D. Ugrinovich. – M.: BINOM. Vědomostní laboratoř, 2003. - 512 s.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n