Tableaux d'encodage des données. Codage d'informations textuelles dans un ordinateur
En entrant informations textuelles Dans un ordinateur, les caractères (lettres, chiffres, signes) sont codés à l'aide de divers systèmes de code, qui consistent en un ensemble de tables de codes situées sur les pages correspondantes des normes de codage des informations textuelles. Dans de tels tableaux, chaque caractère se voit attribuer un code numérique spécifique dans un système numérique hexadécimal ou décimal, c'est-à-dire que les tableaux de codes reflètent la correspondance entre les images de symboles et les codes numériques et sont destinés au codage et au décodage des informations textuelles. Lors de la saisie d'informations textuelles à l'aide d'un clavier d'ordinateur, chaque caractère saisi est codé, c'est-à-dire converti en un code numérique ; lorsque les informations textuelles sont sorties vers un périphérique de sortie informatique (écran, imprimante ou traceur), son image est construite à l'aide du code numérique de le personnage. L'attribution d'un code numérique spécifique à un symbole est le résultat d'un accord entre les organisations compétentes de différents pays. Actuellement, il n'existe pas de table de codes universelle unique correspondant aux lettres des alphabets nationaux des différents pays.
Les tables de codes modernes comprennent des parties internationales et nationales, c'est-à-dire qu'elles contiennent des lettres des alphabets latin et national, des chiffres, des opérations arithmétiques et des signes de ponctuation, des symboles mathématiques et de contrôle et des symboles pseudographiques. Partie internationale de la table de codes basée sur la norme ASCII (code standard américain pour l'échange d'informations), encode la première moitié des caractères de la table de codes avec des codes numériques de 0 à 7 F 16, ou dans le système de nombres décimaux de 0 à 127. Dans ce cas, des codes de 0 à 20 16 (0 ? 32 10) sont attribués aux touches de fonction (F1, F2, F3, etc.) du clavier de l'ordinateur personnel. En figue. 3.1 montre la partie internationale des tables de codes basées sur la norme ASCII. Les cellules du tableau sont numérotées respectivement selon des systèmes de nombres décimaux et hexadécimaux.

Graphique 3.1. Partie internationale de la table des codes (standard ASCII) avec les numéros de cellules présentés dans les systèmes numériques décimaux (a) et hexadécimaux (b)
La partie nationale des tables de codes contient les codes des alphabets nationaux, également appelée table des jeux de caractères. (jeu de caractères).
Actuellement, pour prendre en charge les lettres de l'alphabet russe (cyrillique), il existe plusieurs tables de codes (codages) utilisées par divers systèmes d'exploitation, ce qui constitue un inconvénient important et conduit dans certains cas à des problèmes liés aux opérations de décodage des valeurs de caractères numériques. Dans le tableau 3.1 montre les noms des pages de codes (normes) sur lesquelles se trouvent les tables de codes cyrilliques (codages).
Tableau 3.1
L'une des premières normes d'encodage de l'alphabet cyrillique sur les ordinateurs était la norme KOI8-R. La partie nationale de la table de codes de cette norme est illustrée à la Fig. 3.2.

Riz. 3.2. Partie nationale de la table de codes de la norme KOI8-R
Actuellement, la table de codes située à la page CP866 de la norme de codage des informations textuelles, utilisée dans le système d'exploitation, est également utilisée MS-DOS ou séance MS-DOS pour coder l'alphabet cyrillique (Fig. 3.3, UN).


Riz. 3.3. La partie nationale de la table de codes, située à la page CP866 (a) et à la page CP1251 (b) de la norme de codage des informations textuelles
Actuellement, pour coder l'alphabet cyrillique, la table de codes la plus utilisée se trouve à la page CP1251 de la norme correspondante, qui est utilisée dans systèmes d'exploitation ah la famille les fenêtres entreprises Microsoft(Fig. 3.2, b). Dans toutes les tables de codes présentées, à l'exception de la table standard Unicode Pour coder un caractère, 8 chiffres binaires (8 bits) sont alloués.
A la fin du siècle dernier, une nouvelle norme internationale est apparue Unicode dans lequel un caractère est représenté sous la forme d'un code binaire à deux octets. L'application de cette norme s'inscrit dans la continuité du développement d'une norme internationale universelle visant à résoudre le problème de la compatibilité des codages de caractères nationaux. Grâce à cette norme, 2 16 = 65 536 caractères différents peuvent être codés. En figue. 3.4 montre la table de codes 0400 (alphabet russe) de la norme Unicode.
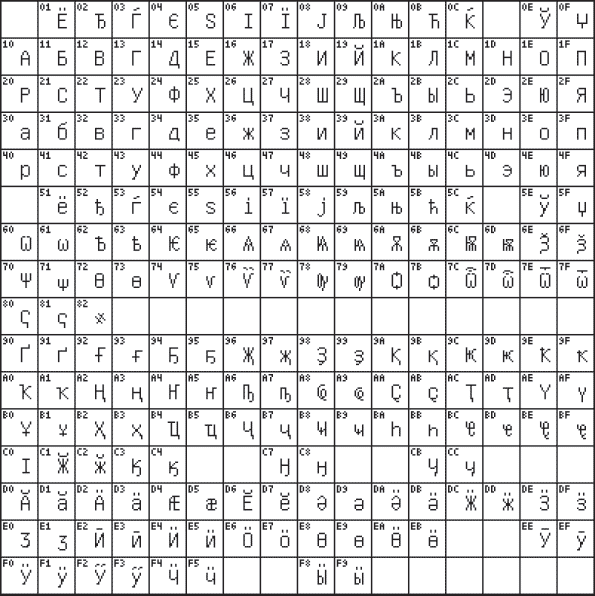
Riz. 3.4. Table de codes Unicode 0400
Expliquons ce qui a été dit concernant le codage des informations textuelles à l'aide d'un exemple.
Exemple 3.1Encodez le mot « Ordinateur » sous la forme d’une séquence de nombres décimaux et hexadécimaux à l’aide du codage CP1251. Quels caractères seront affichés dans les tables de codes CP866 et KOI8-R lors de l'utilisation du code reçu.
Séquences de code hexadécimal et binaire du mot « Ordinateur » basées sur la table de codage CP1251 (voir Fig. 3.3, b) ressemblera à ceci :
Cette séquence de codes dans les encodages SR866 et KOI8-R entraînera l'affichage des caractères suivants :
Pour convertir des documents texte en langue russe d'une norme de codage d'informations textuelles à une autre, des programmes spéciaux sont utilisés - des convertisseurs. Les convertisseurs sont généralement intégrés à d'autres programmes. Un exemple serait un programme de navigation - Internet Explorer (IE), qui a un convertisseur intégré. Un programme de navigation est un programme spécial permettant d'afficher du contenu. les pages Web sur le réseau informatique mondial Internet. Utilisons ce programme pour confirmer le résultat du mappage de symboles obtenu dans l'exemple 3.1. Pour ce faire, nous effectuerons les étapes suivantes.
1. Lancez le programme Bloc-notes (Bloc-notes). Programme Bloc-notes dans le système d'exploitation Windows XP lancé à l'aide de la commande : [Bouton Commencer– Programmes – Standard – Bloc-notes]. Dans la fenêtre du programme Bloc-notes qui s'ouvre, tapez le mot « Ordinateur » en utilisant la syntaxe du langage de balisage de document hypertexte - HTML (langage de balisage hypertexte). Ce langage est utilisé pour créer des documents sur Internet. Le texte devrait ressembler à ceci :
Eau informatique
, OùEt
balises (constructions spéciales) du langage HTML pour le balisage d’en-tête. En figue. La figure 3.5 montre le résultat de ces actions.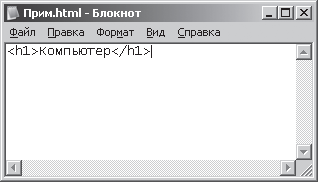
Riz. 3.5. Afficher du texte dans la fenêtre du Bloc-notes
Sauvons ce texte en exécutant la commande : [Fichier - Enregistrer sous...] dans le dossier approprié sur l'ordinateur, lors de l'enregistrement du texte, nous donnerons au fichier un nom - Note, avec une extension de fichier. html.
2. Lançons le programme Internet Explorer, en exécutant la commande : [Bouton Commencer- Programmes - Internet Explorer]. Lorsque vous démarrez le programme, la fenêtre illustrée à la Fig. 3.6
Riz. 3.6. Fenêtre d'accès hors ligne
Sélectionnez et activez le bouton Hors ligne Dans ce cas, l'ordinateur ne se connectera pas à l'Internet mondial. La fenêtre principale du programme apparaîtra Microsoft Internet Explorer, montré sur la fig. 3.7.
Riz. 3.7. Fenêtre principale de Microsoft Internet Explorer
Exécutons la commande suivante : [Fichier – Ouvrir], une fenêtre apparaîtra (Fig. 3.8), dans laquelle vous devez spécifier le nom du fichier et cliquer sur le bouton D'ACCORD ou appuyez sur le bouton Revoir… et recherchez le fichier Prim.html.

Riz. 3.8. Fenêtre ouverte
La fenêtre principale du programme Internet Explorer prendra la forme illustrée à la Fig. 3.9. Le mot « Ordinateur » apparaîtra dans la fenêtre. Ensuite, en utilisant le menu supérieur du programme Internet Explorer, exécutez la commande suivante : [Affichage – Encodage – Cyrillique (DOS)]. Après avoir exécuté cette commande dans la fenêtre du programme Internet Explorer Les symboles illustrés sur la Fig. seront affichés. 3.10. Lors de l’exécution de la commande : [Affichage – Encodage – Cyrillique (KOI8-R)] dans la fenêtre du programme Internet Explorer Les symboles illustrés sur la Fig. seront affichés. 3.11.

Riz. 3.9. Caractères affichés avec encodage CP1251
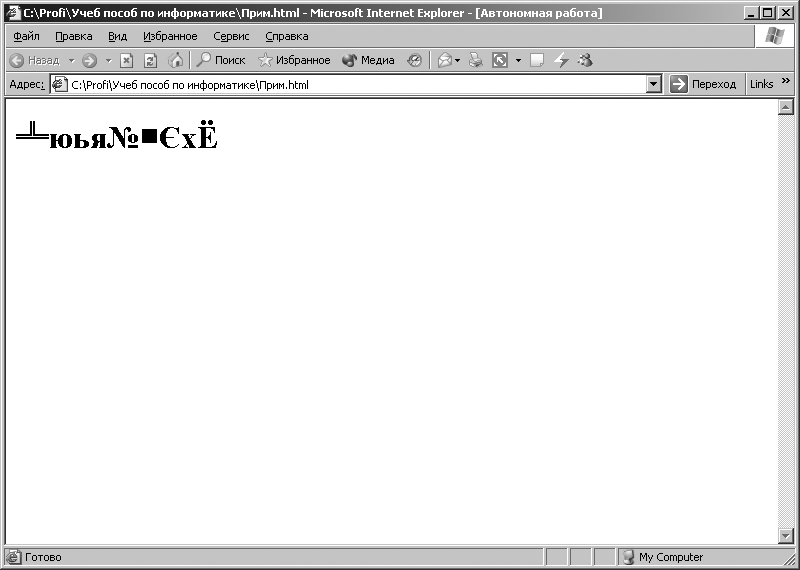
Riz. 3.10. Caractères affichés lorsque le codage CP866 est activé pour une séquence de code représentée dans le codage CP1251
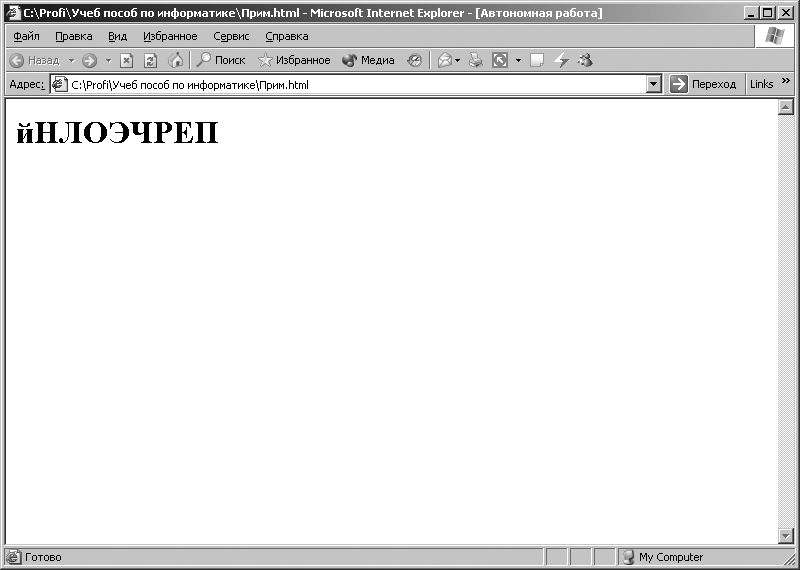
Riz. 3.11. Caractères affichés lorsque le codage KOI8-R est activé pour une séquence de code représentée dans le codage CP1251
Ainsi, obtenu à l'aide du programme Internet Explorer les séquences de caractères coïncident avec les séquences de caractères obtenues à l'aide des tables de codes CP866 et KOI8-R dans l'exemple 3.1.
3.2. Encodage des informations graphiques
Les informations graphiques présentées sous forme d'images, de photographies, de diapositives, d'images animées (animation, vidéo), de diagrammes, de dessins peuvent être créées et modifiées à l'aide d'un ordinateur et sont codées en conséquence. Il y en a actuellement assez un grand nombre de programmes d'application pour le traitement des informations graphiques, mais ils implémentent tous trois types d'infographie : raster, vectoriel et fractal.
Si vous regardez de plus près l'image graphique sur l'écran de l'ordinateur, vous pouvez voir un grand nombre de points multicolores (pixels - de l'anglais. pixels instruit de élément d'image –élément de l’image), qui, rassemblés, forment une image graphique donnée. De là, nous pouvons conclure : une image graphique sur un ordinateur est codée d'une certaine manière et doit être présentée sous la forme d'un fichier graphique. Un fichier est l'unité structurelle de base d'organisation et de stockage des données sur un ordinateur et, dans ce cas, doit contenir des informations sur la manière de présenter cet ensemble de points sur l'écran du moniteur.
Les fichiers créés sur la base de graphiques vectoriels contiennent des informations sous forme de relations mathématiques (fonctions mathématiques décrivant des relations linéaires) et des données correspondantes sur la façon de construire une image d'un objet à l'aide de segments de ligne (vecteurs) lorsqu'il est affiché sur un écran d'ordinateur.
Les fichiers créés sur la base de graphiques raster nécessitent le stockage de données sur chaque point individuel de l'image. Pour afficher des graphiques raster, des calculs mathématiques complexes ne sont pas nécessaires ; il suffit simplement d'obtenir des données sur chaque point de l'image (ses coordonnées et sa couleur) et de les afficher sur l'écran de l'ordinateur.
Au cours du processus de codage, une image est discrétisée spatialement, c'est-à-dire que l'image est divisée en points individuels et chaque point reçoit un code de couleur (jaune, rouge, bleu, etc.). Pour coder chaque point d'une image graphique couleur, on utilise le principe de décomposition d'une couleur arbitraire en ses composants principaux, pour lesquels trois couleurs primaires sont utilisées : le rouge ( mot anglais Rouge, désigné par une lettre À), vert (Vert, désigné par une lettre G), bleu (Bleu, désigné par hêtre DANS). N'importe quelle couleur d'un point perçue par l'œil humain peut être obtenue par addition (mélange) additive (proportionnelle) de trois couleurs primaires - rouge, vert et bleu. Ce système de codage est appelé système de couleurs RVB. Fichiers graphiques utilisant un système de couleurs RVB représenter chaque point de l'image sous la forme d'un triplet de couleurs - trois valeurs numériques R, G Et DANS, correspondant aux intensités de rouge, vert et couleurs bleues. Le processus d'encodage d'une image graphique est réalisé à l'aide de divers moyens techniques (scanner, appareil photo numérique, caméra vidéo numérique, etc.) ; le résultat est une image raster. Lors de la reproduction d'images graphiques couleur sur un écran d'ordinateur couleur, la couleur de chaque point (pixel) d'une telle image est obtenue en mélangeant trois couleurs primaires R, G Et B.
La qualité d'une image raster est déterminée par deux paramètres principaux : la résolution (le nombre de pixels horizontalement et verticalement) et la palette de couleurs utilisée (le nombre de couleurs spécifiées pour chaque pixel de l'image). La résolution est spécifiée en indiquant le nombre de pixels horizontalement et verticalement, par exemple 800 x 600 pixels.
Il existe une relation entre le nombre de couleurs attribuées à un point dans une image raster et la quantité d'informations qui doivent être allouées pour stocker la couleur du point, déterminée par la relation (formule de R. Hartley) :
Où je– la quantité d'informations; N – le nombre de couleurs attribuées au point.
La quantité d'informations nécessaires pour stocker la couleur d'un point est également appelée profondeur de couleur ou qualité du rendu des couleurs.
Ainsi, si le nombre de couleurs spécifié pour un point image est N= 256, alors la quantité d'informations nécessaire à son stockage (profondeur de couleur) conformément à la formule (3.1) sera égale à je= 8 bits.
Les ordinateurs utilisent différents modes graphiques du moniteur pour afficher des informations graphiques. Il convient de noter ici qu'en plus du mode graphique du moniteur, il existe également un mode texte, dans lequel l'écran du moniteur est classiquement divisé en 25 lignes de 80 caractères par ligne. Ces modes graphiques sont caractérisés par la résolution de l'écran du moniteur et la qualité des couleurs (profondeur des couleurs). Pour définir le mode graphique de l'écran du moniteur dans le système d'exploitation MS Windows XP vous devez exécuter la commande : [Bouton Commencer– Paramètres – Panneau de configuration – Écran]. Dans la boîte de dialogue « Propriétés : Écran » qui apparaît (Fig. 3.12), vous devez sélectionner l'onglet « Paramètres » et utiliser le curseur « Résolution d'écran » pour sélectionner la résolution d'écran appropriée (800 par 600 pixels, 1024 par 768 pixels, etc.). À l'aide de la liste déroulante « Qualité des couleurs », vous pouvez sélectionner la profondeur de couleur - « La plus élevée (32 bits) », « Moyenne (16 bits) », etc., et le nombre de couleurs attribuées à chaque point de l'image sera être respectivement 2 32 (4294967296), 2 16 (65536), etc.

Riz. 3.12. Boîte de dialogue Propriétés d'affichage
Pour mettre en œuvre chacun des modes graphiques de l'écran du moniteur, une certaine quantité de mémoire vidéo informatique est requise. Volume d'informations requis de la mémoire vidéo (V) est déterminé à partir de la relation
Où À - nombre de points d'image sur l'écran du moniteur (K = A · B) ; UN - nombre de points horizontaux sur l'écran du moniteur ; DANS - nombre de points verticaux sur l'écran du moniteur ; je– quantité d'informations (profondeur de couleur).
Ainsi, si l'écran du moniteur a une résolution de 1 024 x 768 pixels et une palette composée de 65 536 couleurs, alors la profondeur de couleur selon la formule (3.1) sera I = log 2 65 538 = 16 bits, le nombre de pixels de l'image sera être égal à: K = 1024 x 768 = 786432, et le volume d'informations requis de la mémoire vidéo conformément à (3.2) sera égal à
V= 786432 · 16 bits = 12582912 bits = 1572864 octets = 1536 Ko = 1,5 Mo.
En conclusion, il convient de noter qu'en plus des caractéristiques énumérées, les caractéristiques les plus importantes d'un moniteur sont les dimensions géométriques de son écran et des points d'image. Les dimensions géométriques de l'écran sont déterminées par la taille diagonale du moniteur. La taille diagonale des moniteurs est spécifiée en pouces (1 pouce = 1" = 25,4 mm) et peut prendre des valeurs égales à : 14", 15", 17", 21", etc. Les technologies modernes de production de moniteurs peuvent fournir une image taille de point égale à 0,22 mm.
Ainsi, pour chaque moniteur, il existe une résolution d'écran physiquement maximale possible, déterminée par la taille de sa diagonale et la taille du point d'image.
Exercices à faire soi-même
1. Utiliser le programme MS Excel convertir les tables de codes ASCII, SR866, SR1251, KOI8-R en tables de la forme : dans les cellules de la première colonne des tableaux écrire par ordre alphabétique les lettres majuscules puis minuscules de l'alphabet latin et cyrillique, dans les cellules du deuxième colonne - les codes correspondant aux lettres du système numérique décimal, dans les cellules la troisième colonne contient les codes correspondant aux lettres du système numérique hexadécimal. Les valeurs de code doivent être sélectionnées dans les tables de codes correspondantes.
2. Encodez et notez les mots suivants sous la forme d'une séquence de nombres dans les systèmes numériques décimaux et hexadécimaux :
un) Internet Explorer, b) Microsoft Office; V) CorelDRAW.
L'encodage est réalisé à l'aide de la table d'encodage ASCII modernisée obtenue lors de l'exercice précédent.
3. À l'aide de la table de codage KOI8-R modernisée, décodez les séquences de nombres écrits dans le système numérique hexadécimal :
a) FC CB DA C9 D3 D4 C5 CE C3 C9 D1 ;
b) EB CF CE C6 CF D2 CD C9 DA CD ;
c) FC CB D3 D0 D2 C5 D3 C9 CF CE C9 DA CD.
4. À quoi ressemblera le mot « Cybernétique » écrit en codage SR1251 lors de l'utilisation des codages SR866 et KOI8-R ? Vérifiez les résultats à l'aide du programme Internet Explorer.
5. En utilisant la table de codes illustrée à la Fig. 3.1 UN, décoder les séquences de codes suivantes écrites dans le système de nombres binaires :
a) 01010111 01101111 01110010 01100100 ;
b) 01000101 01111000 01100011 01100101 01101100 ;
c) 01000001 01100011 01100011 01100101 01110011 01110011.
6. Déterminez le volume d'informations du mot « Économie », codé à l'aide des tables de codes SR866, SR1251, Unicode et KOI8-R.
7. Déterminez le volume d'informations du fichier obtenu à la suite de la numérisation d'une image couleur mesurant 12x12 cm. La résolution du scanner utilisé pour numériser cette image est de 600 dpi. Le scanner définit la profondeur de couleur du point d'image sur 16 bits.
Résolution du scanner 600 dpi (pouce de pointeur - points par pouce) détermine la capacité d'un scanner avec cette résolution à distinguer 600 points sur un segment de 1 pouce.
8. Déterminez le volume d'informations du fichier obtenu à la suite de la numérisation d'une image couleur au format A4. La résolution du scanner utilisé pour numériser cette image est de 1 200 dpi. Le scanner définit la profondeur de couleur du point d'image sur 24 bits.
9. Déterminez le nombre de couleurs dans la palette avec des profondeurs de couleur de 8, 16, 24 et 32 bits.
10. Déterminez la quantité de mémoire vidéo requise pour les modes graphiques de l'écran du moniteur 640 x 480, 800 x 600, 1024 x 768 et 1280 x 1024 pixels avec une profondeur de couleur des pixels d'image de 8, 16, 24 et 32 bits. Résumez les résultats dans un tableau. Développer dans MS Excel programme pour automatiser les calculs.
11. Déterminez le nombre maximum de couleurs pouvant être utilisées pour stocker une image mesurant 32 x 32 pixels, si l'ordinateur dispose de 2 Ko de mémoire alloués à l'image.
12. Déterminez la résolution maximale possible d'un écran de moniteur avec une diagonale de 15" et une taille de point d'image de 0,28 mm.
13. Quels modes graphiques du moniteur peuvent être fournis par 64 Mo de mémoire vidéo ?
Matériel d'auto-apprentissage sur le thème de la leçon 2
Codage ASCII
Table de codage ASCII (ASCII - American Standard Code for Information Interchange - American Standard Code for Information Interchange).
Au total, 256 caractères différents peuvent être codés à l'aide de la table de codage ASCII (Figure 1). Ce tableau est divisé en deux parties : la principale (avec les codes de OOh à 7Fh) et la supplémentaire (de 80h à FFh, où la lettre h indique que le code appartient au système numérique hexadécimal).
Image 1
Pour coder un caractère du tableau, 8 bits (1 octet) sont alloués. Lors du traitement d'informations textuelles, un octet peut contenir le code d'un certain caractère - une lettre, un chiffre, un signe de ponctuation, un signe d'action, etc. Chaque caractère possède son propre code sous forme d'entier. Dans ce cas, tous les codes sont collectés dans des tables spéciales appelées tables de codage. Avec leur aide, le code du symbole est converti en sa représentation visible sur l'écran du moniteur. En conséquence, tout texte dans la mémoire de l'ordinateur est représenté comme une séquence d'octets avec des codes de caractères.
Par exemple, le mot bonjour ! seront codés comme suit (tableau 1).
Tableau 1
|
Code binaire | ||||||
|
Code décimal |
La figure 1 montre les caractères inclus dans le codage ASCII standard (anglais) et étendu (russe).
La première moitié du tableau ASCII est standardisée. Il contient des codes de contrôle (de 00h à 20h et 77h). Ces codes ont été supprimés du tableau car ils ne s'appliquent pas aux éléments de texte. Des signes de ponctuation et des symboles mathématiques sont également placés ici : 2lh - !, 26h - &, 28h - (, 2Bh -+,..., grandes et petites lettres latines : 41h - A, 61h – a.
La seconde moitié du tableau contient les polices nationales, les symboles pseudographiques à partir desquels des tableaux peuvent être construits et des symboles mathématiques spéciaux. La partie inférieure de la table de codage peut être remplacée à l'aide de pilotes appropriés - programmes auxiliaires de contrôle. Cette technique permet d'utiliser plusieurs polices et leurs polices de caractères.
L'affichage de chaque code de symbole doit afficher une image du symbole - pas seulement un code numérique, mais une image correspondante, puisque chaque symbole a sa propre forme. Une description de la forme de chaque caractère est stockée dans une mémoire d'affichage spéciale - un générateur de caractères. La mise en évidence d'un caractère sur l'écran d'un afficheur IBM PC, par exemple, s'effectue à l'aide de points formant une matrice de caractères. Chaque pixel d'une telle matrice est un élément d'image et peut être clair ou sombre. Un point sombre est codé par 0, un point clair (lumineux) par 1. Si vous représentez les pixels sombres dans le champ matriciel d'un signe par un point et les pixels clairs par un astérisque, vous pouvez représenter graphiquement la forme du symbole.
Les hommes dans différents pays utiliser des symboles pour écrire des mots dans leur langue maternelle. De nos jours, la plupart des applications, y compris les systèmes de messagerie et les navigateurs Web, sont en pur 8 bits, ce qui signifie qu'elles ne peuvent afficher et accepter correctement que les caractères 8 bits, conformément à la norme ISO-8859-1.
Il existe plus de 256 caractères dans le monde (si l'on prend en compte le cyrillique, l'arabe, le chinois, le japonais, le coréen et le thaï), et de plus en plus de nouveaux caractères apparaissent. Et cela crée les lacunes suivantes pour de nombreux utilisateurs :
Il n'est pas possible d'utiliser des caractères provenant de jeux de codage différents dans le même document. Étant donné que chaque document texte utilise son propre ensemble d'encodages, la reconnaissance automatique du texte présente de grandes difficultés.
De nouveaux symboles apparaissent (par exemple : Euro), à la suite desquels l'ISO développe une nouvelle norme, ISO-8859-15, très similaire à la norme ISO-8859-1. La différence est que l'ancienne table de codage ISO-8859-1 a supprimé les symboles des anciennes monnaies qui ne sont pas actuellement utilisées pour faire place aux symboles nouvellement introduits (tels que l'euro). En conséquence, les utilisateurs peuvent avoir les mêmes documents sur leurs disques, mais dans des encodages différents. La solution à ces problèmes réside dans l’adoption d’un ensemble international unique de codages appelé Universal Coding ou Unicode.
Codage Unicode
La norme a été proposée en 1991 par l'organisation à but non lucratif Unicode Consortium (Unicode Inc.). L'utilisation de ce standard permet de coder très grand nombre caractères provenant de différents scripts : les documents Unicode peuvent contenir des caractères chinois, des symboles mathématiques, des lettres de l'alphabet grec, de l'alphabet latin et cyrillique, et il devient inutile de changer de page de codes.
La norme se compose de deux sections principales : le jeu de caractères universel (UCS) et la famille d'encodage (UTF, format de transformation Unicode). Le jeu de caractères universel spécifie une correspondance biunivoque entre les caractères et les codes - éléments de l'espace de code représentant des entiers non négatifs. Une famille de codage définit la représentation machine d'une séquence de codes UCS.
La norme Unicode a été développée pour créer un codage de caractères unique pour toutes les langues écrites modernes et anciennes. Chaque caractère de cette norme est codé sur 16 bits, ce qui lui permet de couvrir un nombre de caractères incomparablement plus grand que les codages 8 bits précédemment acceptés. Une autre différence importante entre Unicode et les autres systèmes de codage est qu'il attribue non seulement un code unique à chaque caractère, mais définit également diverses caractéristiques de ce caractère, par exemple :
type de caractère (lettre majuscule, lettre minuscule, chiffre, signe de ponctuation, etc.) ;
attributs des caractères (affichage de gauche à droite ou de droite à gauche, espace, saut de ligne, etc.) ;
la lettre majuscule ou minuscule correspondante (pour les lettres minuscules et majuscules, respectivement) ;
la valeur numérique correspondante (pour les caractères numériques).
L'ensemble des codes de 0 à FFFF est divisé en plusieurs sous-ensembles standards, chacun correspondant soit à l'alphabet d'une langue, soit à un groupe de caractères spéciaux similaires dans leurs fonctions. Le diagramme ci-dessous contient une liste générale des sous-ensembles Unicode 3.0 (Figure 2).

Figure 2
La norme Unicode constitue la base du stockage de texte dans de nombreux systèmes informatiques modernes. Cependant, il n'est pas compatible avec la plupart des protocoles Internet car ses codes peuvent contenir n'importe quelle valeur d'octet, et les protocoles utilisent généralement les octets 00 à 1F et FE à FF comme octets de service. Pour assurer la compatibilité, plusieurs formats de transformation Unicode (UTF) ont été développés, dont UTF-8 est de loin le plus courant. Ce format définit les règles suivantes pour convertir chaque code Unicode en un ensemble d'octets (un à trois) adaptés au transport par les protocoles Internet.
Ici, x, y, z désignent les bits du code source qui doivent être extraits, en commençant par le moins significatif, et entrés dans les octets de résultat de droite à gauche jusqu'à ce que toutes les positions spécifiées soient remplies.
Le développement ultérieur de la norme Unicode est associé à l'ajout de nouveaux plans de langage, c'est-à-dire caractères dans les plages 10000 - 1FFFF, 20000 - 2FFFF, etc., où il est censé inclure le codage pour les scripts de langues mortes qui ne sont pas incluses dans le tableau ci-dessus. Un nouveau format, UTF-16, a été développé pour coder ces caractères supplémentaires.
Il existe donc 4 manières principales d'encoder des octets Unicode :
UTF-8 : 128 caractères codés sur un octet (format ASCII), 1920 caractères codés sur 2 octets ((caractères romains, grecs, cyrilliques, coptes, arméniens, hébreux, arabes), 63488 caractères codés sur 3 octets (chinois, japonais, etc. .) Les 2 147 418 112 caractères restants (non encore utilisés) peuvent être codés sur 4, 5 ou 6 octets.
UCS-2 : Chaque caractère est représenté par 2 octets. Cet encodage inclut uniquement les 65 535 premiers caractères du format Unicode.
UTF-16 : Extension d'UCS-2, il contient 1 114 112 caractères au format Unicode. Les 65 535 premiers caractères sont représentés par 2 octets, le reste par 4 octets.
USC-4 : Chaque caractère est codé sur 4 octets.
Encodage des informations textuelles
Rappelons quelques faits que nous connaissons :
L'ensemble de caractères avec lequel le texte est écrit est appeléalphabet.
Le nombre de caractères de l'alphabet est sonpouvoir.
Formule pour déterminer la quantité d'informations :N=2b,
où N est la puissance de l'alphabet (nombre de caractères),
b - nombre de bits (poids informationnel du symbole).
L'alphabet d'une capacité de 256 caractères peut accueillir presque tous les caractères nécessaires. Cet alphabet s'appellesuffisant.
Parce que 256 = 28 , alors le poids d'un caractère est de 8 bits.
L'unité de mesure 8 bits a reçu le nom1 octet :
1 octet = 8 bits.
Le code binaire de chaque caractère du texte informatique occupe 1 octet de mémoire.
Comment les informations textuelles sont-elles représentées dans la mémoire de l’ordinateur ?
|
| Les textes sont saisis dans la mémoire de l'ordinateur à l'aide du clavier. Les lettres, chiffres, signes de ponctuation et autres symboles que nous connaissons sont inscrits sur les touches. Ils entrent dans la RAM en code binaire. Cela signifie que chaque caractère est représenté par un code binaire de 8 bits. Le codage consiste à attribuer à chaque caractère un code décimal unique de 0 à 255 ou un code binaire correspondant de 00000000 à 11111111. Ainsi, une personne distingue les caractères par leur contour, et un ordinateur par leur code. |

La commodité du codage de caractères octet par octet est évidente car un octet est la plus petite partie adressable de la mémoire et, par conséquent, le processeur peut accéder à chaque caractère séparément lors du traitement du texte. En revanche, 256 caractères sont un nombre tout à fait suffisant pour représenter une grande variété d’informations symboliques.
La question se pose maintenant de savoir quel code binaire de huit bits attribuer à chaque caractère.
Il est clair qu'il s'agit d'une question conditionnelle ; vous pouvez proposer de nombreuses méthodes de codage.
Tous les caractères de l'alphabet informatique sont numérotés de 0 à 255. Chaque numéro correspond à un code binaire de huit bits allant de 00000000 à 11111111. Ce code est simplement le numéro de série du caractère dans le système de numérotation binaire.
Une table dans laquelle tous les caractères de l'alphabet informatique se voient attribuer des numéros de série est appelée table de codage.
Pour différents types Les ordinateurs utilisent différentes tables de codage.
La table est devenue la norme internationale pour les PCASCII(lire aski) (American Standard Code for Information Interchange).
La table des codes ASCII est divisée en deux parties.
Seule la première moitié du tableau constitue la norme internationale, c'est-à-dire symboles avec des chiffres de0 (00000000), jusqu'à127 (01111111).
Structure du tableau Encodages ASCII
| Numéro de série | Code | Symbole |
| 0 - 31 | 00000000 - 00011111 | Les symboles comportant des nombres de 0 à 31 sont généralement appelés symboles de contrôle. |
| 32 - 127 | 00100000 - 01111111 | Partie standard du tableau (anglais). Cela inclut les lettres minuscules et majuscules de l’alphabet latin, les nombres décimaux, les signes de ponctuation, toutes sortes de parenthèses, les symboles commerciaux et autres. |
| 128 - 255 | 10000000 - 11111111 | Partie alternative du tableau (russe). |
Première moitié de la table de codes ASCII
|
|

Veuillez noter que dans le tableau d'encodage, les lettres (majuscules et minuscules) sont classées par ordre alphabétique et les chiffres sont classés par ordre croissant. Ce respect de l'ordre lexicographique dans la disposition des symboles est appelé principe du codage séquentiel de l'alphabet.
Pour les lettres de l'alphabet russe, le principe du codage séquentiel est également respecté.
Deuxième moitié de la table de codes ASCII

Malheureusement, il existe actuellement cinq encodages cyrilliques différents (KOI8-R, Windows. MS-DOS, Macintosh et ISO). Pour cette raison, des problèmes surviennent souvent lors du transfert de texte russe d'un ordinateur à un autre, d'un système logiciel à un autre.
Chronologiquement, l'une des premières normes de codage des lettres russes sur les ordinateurs était KOI8 (« Information Exchange Code, 8-bit »). Ce codage a été utilisé dans les années 70 sur les ordinateurs de la série ES et, à partir du milieu des années 80, il a commencé à être utilisé dans les premières versions russifiées du système d'exploitation UNIX.
Depuis le début des années 90, époque de domination du système d'exploitation MS DOS, l'encodage CP866 demeure (« CP » signifie « Code Page », « code page »).
Les ordinateurs Apple exécutant le système d'exploitation Mac OS utilisent leur propre encodage Mac.
En outre, l'Organisation internationale de normalisation (ISO) a approuvé un autre codage appelé ISO 8859-5 comme norme pour la langue russe.
Le codage le plus couramment utilisé actuellement est Microsoft Windows, en abrégé CP1251.
Depuis la fin des années 90, le problème de la normalisation du codage des caractères a été résolu par l'introduction d'une nouvelle norme internationale appeléeUnicode. Il s'agit d'un encodage 16 bits, c'est-à-dire il alloue 2 octets de mémoire pour chaque caractère. Bien entendu, cela multiplie par 2 la quantité de mémoire occupée. Mais une telle table de codes permet d'inclure jusqu'à 65 536 caractères. La spécification complète de la norme Unicode comprend tous les alphabets du monde existants, disparus et créés artificiellement, ainsi que de nombreux symboles mathématiques, musicaux, chimiques et autres.
Essayons d'utiliser un tableau ASCII pour imaginer à quoi ressembleront les mots dans la mémoire de l'ordinateur.
Représentation interne des mots dans la mémoire de l'ordinateur
| Mots | Mémoire |
| déposer | 01100110 01101001 01101100 01100101 |
| disque | 01100100 01101001 01110011 01101011 |
Parfois, il arrive qu'un texte composé de lettres de l'alphabet russe reçu d'un autre ordinateur ne puisse pas être lu - une sorte d'« abracadabra » est visible sur l'écran du moniteur. Cela se produit parce que les ordinateurs utilisent des codages de caractères différents pour la langue russe.
Contenu
I. Historique du codage des informations……………………………..3
II. Codage des informations……………………………………………………4
III. Codage des informations textuelles…………………………….4
IV. Types de tables de codage……………………………………………………...6
V. Calcul de la quantité d'informations textuelles………………………14
Liste des références……………………………..16
je . Histoire du codage de l'information
L'humanité utilise le cryptage (codage) de texte depuis le moment même où les premières informations secrètes sont apparues. Voici plusieurs techniques d'encodage de texte qui ont été inventées à différentes étapes du développement de la pensée humaine :
La cryptographie est une écriture secrète, un système de modification de l'écriture afin de rendre le texte incompréhensible pour les non-initiés ;
Code Morse ou code télégraphique impair, dans lequel chaque lettre ou signe est représenté par sa propre combinaison de puces courtes courant électrique(points) et parcelles élémentaires de durée triple (tiret) ;
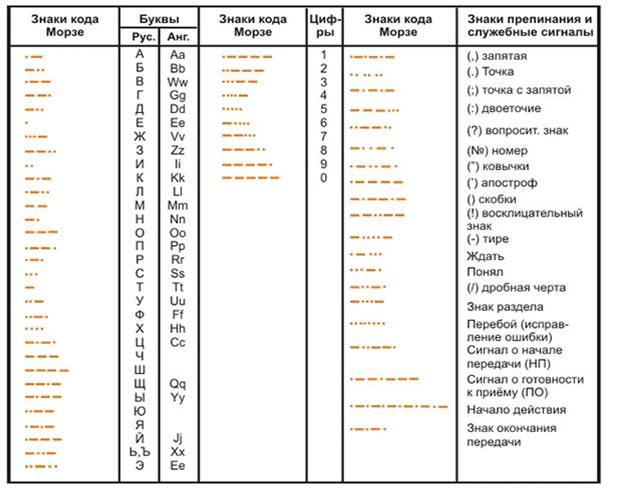 la langue des signes est une langue des signes utilisée par les personnes malentendantes.
la langue des signes est une langue des signes utilisée par les personnes malentendantes. L'un des tout premiers méthodes connues Le cryptage doit son nom à l'empereur romain Jules César (1er siècle avant JC). Cette méthode est basée sur le remplacement de chaque lettre du texte crypté par une autre, en décalant l'alphabet de la lettre d'origine d'un nombre fixe de caractères, et l'alphabet est lu en cercle, c'est-à-dire qu'après la lettre i, a est considéré . Ainsi, le mot « octet », lorsqu'il est décalé de deux caractères vers la droite, est codé comme le mot « gwlf ». Le processus inverse de déchiffrement d'un mot donné est nécessaire pour remplacer chaque lettre cryptée par la seconde à sa gauche.
II. Informations d'encodage
Un code est un ensemble de conventions (ou signaux) permettant d'enregistrer (ou de communiquer) des concepts prédéfinis.
Le codage de l’information est le processus de formation d’une représentation spécifique de l’information. Dans un sens plus étroit, le terme « codage » est souvent compris comme une transition d'une forme de représentation de l'information à une autre, plus pratique pour le stockage, la transmission ou le traitement.
Habituellement, chaque image lors du codage (parfois appelé cryptage) est représentée par un signe distinct.
Un signe est un élément d’un ensemble fini d’éléments distincts les uns des autres.
Dans un sens plus étroit, le terme « codage » est souvent compris comme une transition d'une forme de représentation de l'information à une autre, plus pratique pour le stockage, la transmission ou le traitement.
Vous pouvez traiter des informations textuelles sur un ordinateur. Lorsqu'elle est saisie dans un ordinateur, chaque lettre est codée avec un certain nombre, et lorsqu'elle est sortie sur des périphériques externes (écran ou impression), des images de lettres sont construites à partir de ces chiffres pour la perception humaine. La correspondance entre un ensemble de lettres et de chiffres est appelée codage de caractères.
En règle générale, tous les nombres dans un ordinateur sont représentés par des zéros et des uns (et non par dix chiffres, comme c'est l'habitude pour les gens). En d’autres termes, les ordinateurs fonctionnent généralement selon le système de nombres binaires, car cela simplifie considérablement les dispositifs permettant de les traiter. La saisie de nombres dans un ordinateur et leur sortie pour une lecture humaine peuvent être effectuées sous la forme décimale habituelle, et toutes les conversions nécessaires sont effectuées par des programmes exécutés sur l'ordinateur.
III. Encodage des informations textuelles
La même information peut être présentée (codée) sous plusieurs formes. Avec l'avènement des ordinateurs, il est devenu nécessaire de coder tous les types d'informations traitées à la fois par un individu et par l'humanité dans son ensemble. Mais l’humanité a commencé à résoudre le problème du codage des informations bien avant l’avènement des ordinateurs. Les réalisations grandioses de l'humanité - l'écriture et l'arithmétique - ne sont rien de plus qu'un système de codage de la parole et des informations numériques. L’information n’apparaît jamais sous sa forme pure, elle est toujours présentée d’une manière ou d’une autre, codée d’une manière ou d’une autre.
Le codage binaire est l'un des moyens courants de représenter l'information. Dans les ordinateurs, les robots et les machines à commande numérique, en règle générale, toutes les informations traitées par l'appareil sont codées sous forme de mots de l'alphabet binaire.
Depuis la fin des années 60, les ordinateurs sont de plus en plus utilisés pour traiter des informations textuelles, et actuellement la majeure partie des ordinateurs personnels dans le monde (et la plupart du temps) sont occupés au traitement d'informations textuelles. Tous ces types d'informations dans un ordinateur sont présentés sous forme de code binaire, c'est-à-dire qu'un alphabet de puissance deux est utilisé (seulement deux caractères 0 et 1). Cela est dû au fait qu'il est pratique de représenter l'information sous la forme d'une séquence d'impulsions électriques : il n'y a pas d'impulsion (0), il y a une impulsion (1).
Un tel codage est généralement appelé binaire, et les séquences logiques de zéros et de uns elles-mêmes sont appelées langage machine.
D'un point de vue informatique, le texte est constitué de caractères individuels. Les symboles comprennent non seulement des lettres (majuscules ou minuscules, latines ou russes), mais aussi des chiffres, des signes de ponctuation, des caractères spéciaux tels que "=", "(", "&", etc., et même (faites particulièrement attention !) espaces entre les mots.
Les textes sont saisis dans la mémoire de l'ordinateur à l'aide du clavier. Les lettres, chiffres, signes de ponctuation et autres symboles que nous connaissons sont inscrits sur les touches. Ils entrent dans la RAM en code binaire. Cela signifie que chaque caractère est représenté par un code binaire de 8 bits.
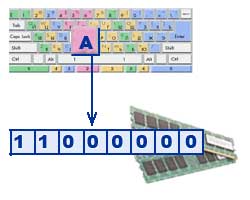 Traditionnellement, pour coder un caractère, une quantité d'informations égale à 1 octet est utilisée, c'est-à-dire I = 1 octet = 8 bits. À l'aide d'une formule qui relie le nombre d'événements possibles K et la quantité d'informations I, vous pouvez calculer combien de symboles différents peuvent être codés (en supposant que les symboles sont des événements possibles) : K = 2 I = 2 8 = 256, c'est-à-dire pour To représentent des informations textuelles, vous pouvez utiliser un alphabet d’une capacité de 256 caractères.
Traditionnellement, pour coder un caractère, une quantité d'informations égale à 1 octet est utilisée, c'est-à-dire I = 1 octet = 8 bits. À l'aide d'une formule qui relie le nombre d'événements possibles K et la quantité d'informations I, vous pouvez calculer combien de symboles différents peuvent être codés (en supposant que les symboles sont des événements possibles) : K = 2 I = 2 8 = 256, c'est-à-dire pour To représentent des informations textuelles, vous pouvez utiliser un alphabet d’une capacité de 256 caractères. Ce nombre de caractères est tout à fait suffisant pour représenter des informations textuelles, notamment les lettres majuscules et minuscules de l'alphabet russe et latin, les chiffres, les signes, les symboles graphiques, etc.
Le codage consiste à attribuer à chaque caractère un code décimal unique de 0 à 255 ou un code binaire correspondant de 00000000 à 11111111. Ainsi, une personne distingue les caractères par leur contour, et un ordinateur par leur code.
La commodité du codage de caractères octet par octet est évidente car un octet est la plus petite partie adressable de la mémoire et, par conséquent, le processeur peut accéder à chaque caractère séparément lors du traitement du texte. En revanche, 256 caractères sont un nombre tout à fait suffisant pour représenter une grande variété d’informations symboliques.
Lors du processus d'affichage d'un symbole sur un écran d'ordinateur, le processus inverse est effectué - le décodage, c'est-à-dire la conversion du code du symbole en son image. Il est important que l'attribution d'un code spécifique à un symbole soit une question d'accord, qui est enregistrée dans la table des codes.
La question se pose maintenant de savoir quel code binaire de huit bits attribuer à chaque caractère. Il est clair qu'il s'agit d'une question conditionnelle ; vous pouvez proposer de nombreuses méthodes de codage.
Tous les caractères de l'alphabet informatique sont numérotés de 0 à 255. Chaque numéro correspond à un code binaire de huit bits allant de 00000000 à 11111111. Ce code est simplement le numéro de série du caractère dans le système de numérotation binaire.
IV . Types de tables d'encodage
Une table dans laquelle tous les caractères de l'alphabet informatique se voient attribuer des numéros de série est appelée table de codage.
Différents types d'ordinateurs utilisent différentes tables de codage.
La table de codes ASCII (American Standard Code for Information Interchange) a été adoptée comme norme internationale, codant la première moitié des caractères avec des codes numériques de 0 à 127 (les codes de 0 à 32 ne sont pas attribués aux caractères, mais aux touches de fonction) .
La table des codes ASCII est divisée en deux parties.
Seule la première moitié du tableau constitue la norme internationale, c'est-à-dire caractères avec des chiffres de 0 (00000000) à 127 (01111111).
Structure de la table de codage ASCII
| Numéro de série | Code | Symbole |
| 0 - 31 | 00000000 - 00011111 | Les symboles comportant des nombres de 0 à 31 sont généralement appelés symboles de contrôle. Leur fonction est de contrôler le processus d'affichage du texte à l'écran ou d'impression, d'émettre un signal sonore, de baliser le texte, etc. |
| 32 - 127 | 0100000 - 01111111 | Partie standard du tableau (anglais). Cela inclut les lettres minuscules et majuscules de l’alphabet latin, les nombres décimaux, les signes de ponctuation, toutes sortes de parenthèses, les symboles commerciaux et autres. Le caractère 32 est un espace, c'est-à-dire position vide dans le texte. Tous les autres se traduisent par certains signes. |
| 128 - 255 | 10000000 - 11111111 | Partie alternative du tableau (russe). La seconde moitié de la table de codes ASCII, appelée page de codes (128 codes, commençant par 1 000 000 et se terminant par 1 111 1111), peut avoir différentes options, chaque option ayant son propre numéro. La page de codes est principalement utilisée pour prendre en charge les alphabets nationaux autres que le latin. Dans les codages nationaux russes, les caractères de l'alphabet russe sont placés dans cette partie du tableau. |

Première moitié de la table de codes ASCII
Veuillez noter que dans le tableau d'encodage, les lettres (majuscules et minuscules) sont classées par ordre alphabétique et les chiffres sont classés par ordre croissant. Ce respect de l'ordre lexicographique dans la disposition des symboles est appelé principe du codage séquentiel de l'alphabet.
Pour les lettres de l'alphabet russe, le principe du codage séquentiel est également respecté.
Deuxième moitié de la table de codes ASCII
Malheureusement, il existe actuellement cinq encodages cyrilliques différents (KOI8-R, Windows. MS-DOS, Macintosh et ISO). Pour cette raison, des problèmes surviennent souvent lors du transfert de texte russe d'un ordinateur à un autre, d'un système logiciel à un autre.
Chronologiquement, l'une des premières normes de codage des lettres russes sur les ordinateurs était KOI8 (« Information Exchange Code, 8-bit »). Ce codage a été utilisé dans les années 70 sur les ordinateurs de la série ES et, à partir du milieu des années 80, il a commencé à être utilisé dans les premières versions russifiées du système d'exploitation UNIX.
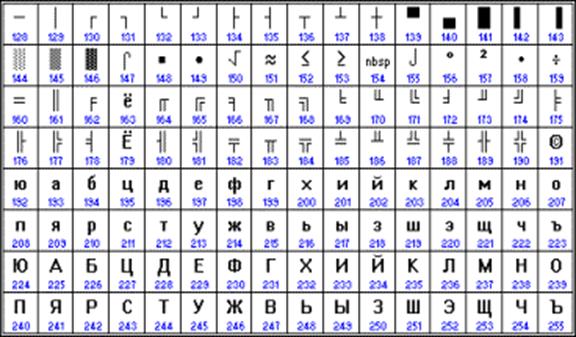
Depuis le début des années 90, époque de domination du système d'exploitation MS DOS, l'encodage CP866 demeure (« CP » signifie « Code Page », « code page »).
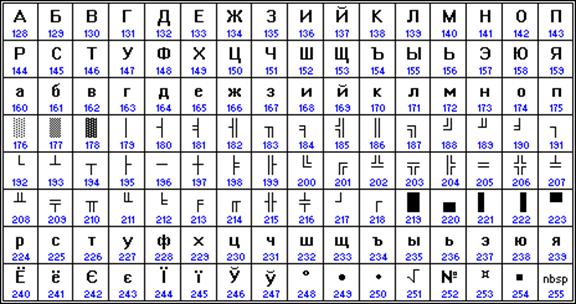
Les ordinateurs Apple exécutant le système d'exploitation Mac OS utilisent leur propre encodage Mac.

En outre, l'Organisation internationale de normalisation (ISO) a approuvé un autre codage appelé ISO 8859-5 comme norme pour la langue russe.

Le codage le plus couramment utilisé actuellement est Microsoft Windows, en abrégé CP1251. Introduit par Microsoft ; compte tenu de la large distribution des systèmes d'exploitation (OS) et autres produits logiciels de cette société dans Fédération Russe il a trouvé une utilisation généralisée.
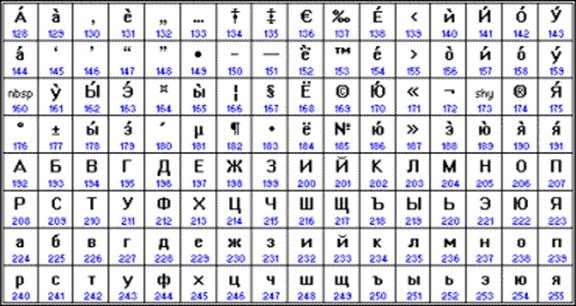
Depuis la fin des années 90, le problème de la normalisation du codage des caractères a été résolu par l'introduction d'un nouveau standard international appelé Unicode.

Il s'agit d'un encodage 16 bits, c'est-à-dire il alloue 2 octets de mémoire pour chaque caractère. Bien entendu, cela multiplie par 2 la quantité de mémoire occupée. Mais une telle table de codes permet d'inclure jusqu'à 65 536 caractères. La spécification complète de la norme Unicode comprend tous les alphabets du monde existants, disparus et créés artificiellement, ainsi que de nombreux symboles mathématiques, musicaux, chimiques et autres.
Représentation interne des mots dans la mémoire de l'ordinateur
en utilisant une table ASCII
Parfois, il arrive qu'un texte composé de lettres de l'alphabet russe reçu d'un autre ordinateur ne puisse pas être lu - une sorte d'« abracadabra » est visible sur l'écran du moniteur. Cela se produit parce que les ordinateurs utilisent des codages de caractères différents pour la langue russe.
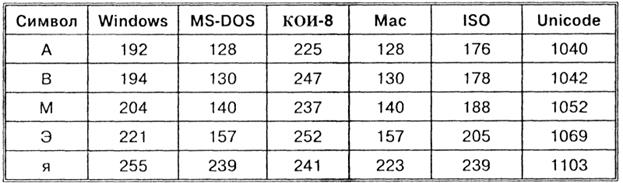
Ainsi, chaque codage est spécifié par sa propre table de codes. Comme le montre le tableau, différents caractères sont attribués au même code binaire dans différents codages.
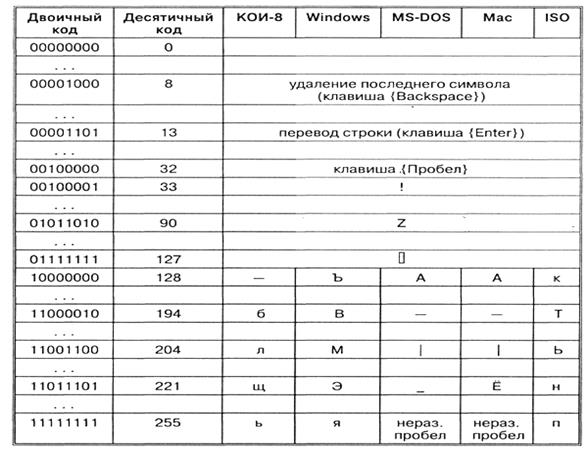 Par exemple, la séquence de codes numériques 221, 194, 204 dans le codage CP1251 forme le mot « ordinateur », alors que dans d'autres codages, ce sera un ensemble de caractères dénué de sens.
Par exemple, la séquence de codes numériques 221, 194, 204 dans le codage CP1251 forme le mot « ordinateur », alors que dans d'autres codages, ce sera un ensemble de caractères dénué de sens. Heureusement, dans la plupart des cas, l'utilisateur n'a pas à se soucier du transcodage des documents texte, car cela est effectué par des programmes de conversion spéciaux intégrés aux applications.
V . Calcul de la quantité d'informations textuelles
Tache 1: Encodez le mot « Rome » à l’aide des tables d’encodage KOI8-R et CP1251.
Solution:

Tâche 2 : En supposant que chaque caractère est codé sur un octet, estimez le volume d'informations de la phrase suivante :
"Mon oncle a les règles les plus honnêtes,
Quand je suis tombé gravement malade,
Il s'est forcé à respecter
Et je ne pouvais penser à rien de mieux.
Solution: Cette phrase comporte 108 caractères, dont des signes de ponctuation, des guillemets et des espaces. On multiplie ce nombre par 8 bits. Nous obtenons 108*8=864 bits.
Tâche 3 : Les deux textes contiennent le même nombre de caractères. Le premier texte est écrit en russe et le second dans la langue de la tribu Naguri, dont l'alphabet est composé de 16 caractères. Quel texte contient plus d’informations ?
Solution:
1) I = K * a (le volume d'informations du texte est égal au produit du nombre de caractères et du poids d'information d'un caractère).
2) Parce que Les deux textes ont le même nombre de caractères (K), la différence dépend donc du contenu informatif d'un caractère de l'alphabet (a).
3) 2 a1 = 32, c'est-à-dire a 1 = 5 bits, 2 a2 = 16, c'est-à-dire et 2 = 4 bits.
4) Je 1 = K * 5 bits, Je 2 = K * 4 bits.
5) Cela signifie que le texte écrit en russe contient 5/4 fois plus d'informations.
Tâche 4 : La taille du message, contenant 2 048 caractères, était de 1/512 de Mo. Déterminez la puissance de l’alphabet.
Solution:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 bits - converti le volume d'informations du message en bits.
2) a = I / K = 16384 /1024 = 16 bits - représente un caractère de l'alphabet.
3) 2*16*2048 = 65536 caractères – la puissance de l'alphabet utilisé.
Tâche 5 : L'imprimante laser Canon LBP imprime à une vitesse moyenne de 6,3 Kbps. Combien de temps faudra-t-il pour imprimer un document de 8 pages, si vous savez qu'une page contient en moyenne 45 lignes et 70 caractères par ligne (1 caractère - 1 octet) ?
Solution:
1) Trouver la quantité d'informations contenues sur 1 page : 45 * 70 * 8 bits = 25200 bits
2) Trouver la quantité d'informations sur 8 pages : 25200 * 8 = 201600 bits
3) Nous réduisons à des unités de mesure communes. Pour ce faire, nous convertissons les Mbits en bits : 6,3*1024=6451,2 bits/sec.
4) Trouvez le temps d'impression : 201600 : 6451,2 = 31 secondes.
Bibliographie
1. Ageev V.M. Théorie de l’information et du codage : échantillonnage et codage des informations de mesure. - M. : MAI, 1977.
2. Kuzmin I.V., Kedrus V.A. Fondamentaux de la théorie de l'information et du codage. - Kyiv, école Vishcha, 1986.
3. Les méthodes les plus simples de cryptage de texte / D.M. Zlatopolski. – M. : Chistye Prudy, 2007 – 32 p.
4. Ugrinovitch N.D. Informatique et informatique. Manuel pour les classes 10-11 / N.D. Ugrinovich. – M. : BINOM. Laboratoire de la Connaissance, 2003. – 512 p.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n



