Кодировка ascii русские символы. Кодирование текстовой информации
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы, например символ «§».
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера.
Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI - American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange - стандартный код информационного обмена США). В системе ASCIIзакреплены две таблицы кодирования - базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII приведена в таблице 1.1.
Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
Так, например, кодировка символов русского языка, известная как кодировка Windows 1251, была введена «извне» - компанией Microsoft , но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 1.2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows .

Другая распространенная кодировка носит название КОИ8 (код обмена информацией, восьмизначный) - ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица1.3). Сегодня кодировка КОИ8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.

Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки ISO (International Standard Organization - Международный институт стандартизации). На практике данная кодировка используется редко (таблица 1.4).

На компьютерах, работающих в операционных системах MS-DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (см. таблицу 1.5).

В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных - это одна из распространенных задач информатики.
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет на много больше. Такая система, основанная на 16разрядном кодировании символов, получила название универсальной - UNICODE .Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов - этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостаточных ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее). Во второй половине 90хгодов технические средства достигли необходимого уровня обеспеченности ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования. Для индивидуальных пользователей это еще больше добавило забот по согласованию документов, выполненных в разных системах кодирования, с программными средствами, но это надо понимать как трудности переходного периода.
Компьютер - сложное устройство, с помощью которого можно создавать, преобразовывать и Однако ЭВМ работает не совсем понятным для нас способом - графические, текстовые и числовые данные хранятся в виде массивов двоичных чисел. В данной статье мы рассмотрим, как осуществляется кодирование текстовой информации.
То, что для нас является текстом, для ЭВМ - последовательность символов. Каждый символ представляет собой определенный набор нулей и единиц. Под символами подразумеваются не только строчные и прописные алфавита, но также и знаки препинания, арифметические знаки, служебные символы, специальные обозначения и даже пробел.
Двоичное кодирование текстовой информации
При нажатии определенной клавиши на внутренний контроллер посылается электрический сигнал, который преобразовывается в Код сопоставляется с определенным символом, который и выводится на экран. Для представления в цифровом формате была создана международная система кодирования ASCII. В ней для записи одного символа необходим 1 байт, следовательно, символ состоит из восьмизначной последовательности нулей и единиц. Интервал записи - от 00000000 до 11111111, то есть кодирование текстовой информации при помощи данной системы позволяет представить 256 символов. В большинстве случаев этого бывает достаточно.
ASCII разделена на две части. Первые 127 символов (от 00000000 до 01111111) являются интернациональными и представляют собой специфические символы и буквы английского алфавита. Вторая же часть - расширение (от 10000000 до 11111111) - предназначена для представления национального алфавита, написание которого отлично от латинского.
Кодирование текстовой информации в ASCII построено по принципу возрастающей последовательности, то есть чем больше порядковый номер латинской буквы, тем больше значение ее ASCII-кода. Цифры и русская часть таблицы построены по тому же принципу.
Однако в мире существует еще несколько видов кодировки для букв кириллицы. Самые распространенные - это КОИ-8 (восьмибитная кодировка, применявшаяся уже в 70-х годах на первых руифицированных ОС Unix), ISO 8859-5 (разработанная Международным бюро стандартизации), СР 1251 (кодирование текстовой информации, применяемое в  современных ОС Windows), а также 2-байтовая кодировка Unicode, с помощью которой можно представить 65536 знаков. Такое многообразие кодировок обусловлено тем, что все они разрабатывались в разное время, для разных операционных систем и из различных соображений. Из-за этого часто возникают трудности при переносе текста с одного носителя на другой - при несовпадении кодировок пользователь увидит лишь набор непонятных значков. Как можно исправить данную ситуацию? В Word, например, при открытии документа выдается сообщение о проблемах с отображением текста и предлагается несколько вариантов перекодирования.
современных ОС Windows), а также 2-байтовая кодировка Unicode, с помощью которой можно представить 65536 знаков. Такое многообразие кодировок обусловлено тем, что все они разрабатывались в разное время, для разных операционных систем и из различных соображений. Из-за этого часто возникают трудности при переносе текста с одного носителя на другой - при несовпадении кодировок пользователь увидит лишь набор непонятных значков. Как можно исправить данную ситуацию? В Word, например, при открытии документа выдается сообщение о проблемах с отображением текста и предлагается несколько вариантов перекодирования.
Итак, кодирование и обработка текстовой информации в недрах компьютера - процесс довольно сложно организованный и трудоемкий. Все символы любого алфавита представляют собой лишь определенную последовательность цифр одна ячейка - это один байт информации.
Рассмотрены основы информатики и описаны современные аппаратные средства персонального компьютера. Сформулированы подходы к определению основных понятий в области информатики и раскрыто их содержание. Дана классификация современных аппаратных средств персонального компьютера и приведены их основные характеристики. Все основные положения иллюстрированы примерами, в которых при решении конкретных задач используются соответствующие программные средства.
Книга:
Разделы на этой странице:
При вводе текстовой информации в компьютер символы (буквы, цифры, знаки) кодируются с помощью различных кодовых систем, которые состоят из набора кодовых таблиц, размещенных на соответствующих страницах стандартов для кодирования текстовой информации. В таких таблицах каждому символу присваивается определенный числовой код в шестнадцатеричной или десятичной системе счисления, т. е. кодовые таблицы отражают соответствие между изображениями символов и числовыми кодами и предназначены для кодирования и декодирования текстовой информации. При вводе текстовой информации с помощью клавиатуры компьютера каждый вводимый символ подвергается кодированию, т. е. преобразуется в числовой код, при выводе текстовой информации на устройство вывода компьютера (дисплей, принтер или плоттер) по числовому коду символа строится его изображение. Присвоение символу определенного числового кода является результатом соглашения между соответствующими организациями разных стран. В настоящее время нет единой универсальной кодовой таблицы, удовлетворяющей буквам национальных алфавитов разных стран.
Современные кодовые таблицы включают в себя международную и национальную части, т. е. содержат буквы латинского и национального алфавитов, цифры, знаки арифметических операций и препинания, математические и управляющие символы, символы псевдографики. Международная часть кодовой таблицы, базирующаяся на стандарте ASCII (American Standard Code for Information Interchange), кодирует первую половину символов кодовой таблицы с числовыми кодами от 0 до 7F 16 , или в десятичной системе счисления от 0 до 127. При этом коды от 0 до 20 16 (0 ? 32 10) отведены функциональным клавишам (F1, F2, F3 и т. д.) клавиатуры персонального компьютера. На рис. 3.1 приведена международная часть кодовых таблиц, основанная на стандарте ASCII. Ячейки таблиц пронумерованы соответственно в десятичной и шестнадцатеричной системе счисления.

Рис 3.1. Международная часть кодовой таблицы (стандарт ASCII) с номерами ячеек, представленных в десятичной (а) и шестнадцатеричной (б) системе счисления
Национальная часть кодовых таблиц содержит коды национальных алфавитов, которую называют также таблицей наборов символов (charset).
В настоящее время для поддержки букв русского алфавита (кириллицы) существует несколько кодовых таблиц (кодировок), которые используются различными операционными системами, что является существенным недостатком и в ряде случаев приводит к проблемам, связанным с операциями декодирования числовых значений символов. В табл. 3.1 приведены названия кодовых страниц (стандартов), на которых размещены кодовые таблицы (кодировки) кириллицы.
Таблица 3.1

Одним из первых стандартов кодирования кириллицы на компьютерах был стандарт КОИ8-Р. Национальная часть кодовой таблицы этого стандарта приведена на рис. 3.2.

Рис. 3.2. Национальная часть кодовой таблицы стандарта КОИ8-Р
В настоящее время применяется и кодовая таблица, размещенная на странице СР866 стандарта кодирования текстовой информации, которая используется в операционной системе MS DOS или сеансе работы MS DOS для кодирования кириллицы (рис. 3.3, а).


Рис. 3.3. Национальная часть кодовой таблицы, размещенная на странице СР866 (а) и на странице СР1251 (б) стандарта кодирования текстовой информации
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица, размещенная на странице СР1251 соответствующего стандарта, которая используется в операционных системах семейства Windows фирмы Microsoft (рис. 3.2, б). Во всех представленных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 2 16 = 65536 различных символов. На рис. 3.4 приведена кодовая таблица 0400 (русский алфавит) стандарта Unicode.
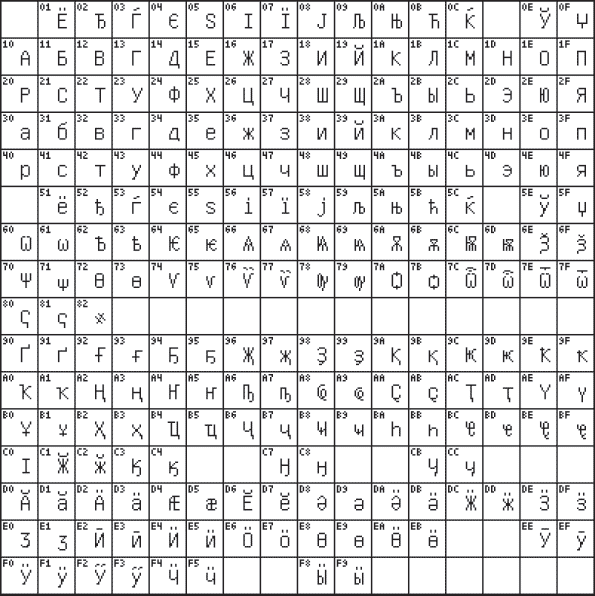
Рис. 3.4. Кодовая таблица 0400 стандарта Unicode
Поясним сказанное, касающееся кодирования текстовой информации, на примере.
Пример 3.1
Закодировать слово «Компьютер» в виде последовательности десятичных и шестнадцатеричных чисел, используя кодировку СР1251. Какие символы будут отображены в кодовых таблицах СР866 и КОИ8-Р при использовании полученного кода.
Последовательности шестнадцатеричного и двоичного кода слова «Компьютер» на основе кодировочной таблицы СР1251 (см. рис. 3.3, б) будут выглядеть следующим образом:
Данная кодовая последовательность в кодировках СР866 и КОИ8-Р приведет к отображению следующих символов:
Для преобразования русскоязычных текстовых документов из одного стандарта кодирования текстовой информации в другой используются специальные программы – конверторы. Конверторы обычно встраиваются в другие программы. Примером может служить программа браузер – Internet Explorer (IE), которая имеет встроенный конвертор. Программа браузер – это специальная программа для просмотра содержимого Web-страниц в глобальной компьютерной сети Интернет. Воспользуемся этой программой для подтверждения полученного в примере 3.1 результата отображения символов. Для этого выполним следующие действия.
1. Запустим программу Блокнот (NotePad). Программа Блокнот в операционной системе Windows ХР запускается с помощью команды: [Кнопка Пуск – Программы – Стандартные – Блокнот]. В открывшемся окне программы Блокнот напечатаем слово «Компьютер» с использованием синтаксиса языка разметки гипертекстовых документов – HTML (Hyper Text Markup Language). Этот язык используется для создания документов в Интернете. Текст должен выглядеть следующим образом:
Компыотер
, гдеи
теги (специальные конструкции) языка HTML для разметки заголовков. На рис. 3.5 представлен результат этих действий.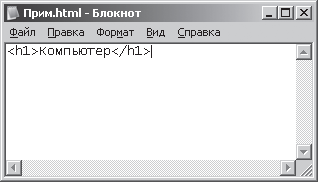
Рис. 3.5. Отображение текста в окне Блокнот
Сохраним этот текст, выполнив команду: [Файл – Сохранить как…] в соответствующей папке компьютера, при сохранении текста файлу присвоим имя – Прим, с расширением файла. html.
2. Запустим программу Internet Explorer, выполнив команду: [Кнопка Пуск – Программы – Internet Explorer]. При запуске программы появится окно, представленное на рис. 3.6
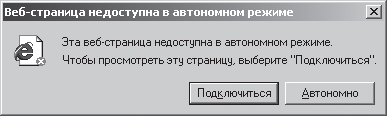
Рис. 3.6. Окно доступа в автономный режим
Выберем и активизируем кнопку Автономно при этом не произойдет подключение компьютера к глобальной сети Интернет. Появится основное окно программы Microsoft Internet Explorer, представленное на рис. 3.7.
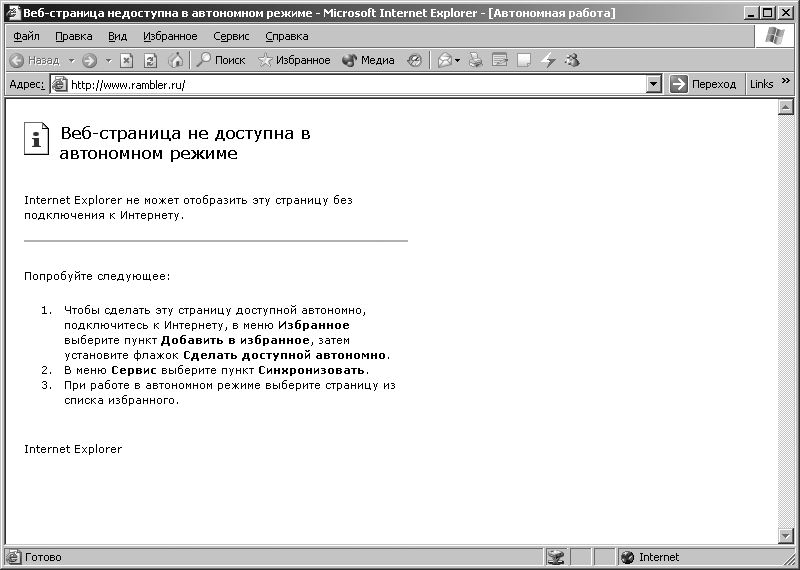
Рис. 3.7. Основное окно Microsoft Internet Explorer
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позволяет размещать в нем любой из алфавитно-цифровых символов. Первые 128 символов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255. Для кодировки русских букв используют различные кодовые таблицы (КОI-8R, СР1251, CP10007, ISO-8859-5):
KOI8 R - восьмибитовый стандарт кодирования букв кириллических алфавитов (для операционной системы UNIX). Разработчики KOI8 R поместили символы русского алфавита в верхней части расширенной таблицы ASCII таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в нижней части таблицы. Это означает, что из текста написанного в KOI8 R , получается текст, написанный латинскими символами. Например, слова «дом высокий» приобретают форму «dom vysokiy»;
СР1251 – восьмибитовый стандарт кодирования, используемый в OS Windows;
CP10007 - восьмибитовый стандарт кодирования, используемый в кириллице операционной системы Macintosh (компьютеров фирмы Apple);
ISO -8859-5 – восьмибитовый код, утвержденный в качестве стандарта для кодирования русского языка.
Кодирование графической информации
Графическую информацию можно представлять в двух формах: аналоговой и дискретной . Живописное полотно , созданное художником, - это пример аналогового представления , а изображение, напечатанное при помощи принтера , состоящее из отдельных (элементов) точек разного цвета, - это дискретное представление .
Путем разбиения графического изображения (дискретизации) происходит преобразование графической информации из аналоговой формы в дискретную. При этом производится кодирование - присвоение каждому элементу графического изображения конкретного значения в форме кода. Создание и хранение графических объектов возможно в нескольких видах - в виде векторного , фрактального или растрового изображения. Отдельным предметом считается 3D (трехмерная) графика , в которой сочетаются векторный и растровый способы формирования изображений.
Векторная графика используется для представления таких графических изображений как рисунки, чертежи, схемы.
Они формируются из объектов - набора геометрических примитивов (точки, линии, окружности, прямоугольники), которым присваиваются некоторые характеристики, например, толщина линий, цвет заполнения.
Изображение в векторном формате упрощает процесс редактирования, так как изображение может без потерь масштабироваться, поворачиваться, деформироваться. При этом каждое преобразование уничтожает старое изображение (или фрагмент), и вместо него строится новое. Такой способ представления хорош для схем и деловой графики. При кодировании векторного изображения хранится не само изображение объекта, а координаты точек, используя которые программа каждый раз воссоздает изображение заново.
Основным недостатком векторной графики является невозможность изображения фотографического качества . В векторном формате изображение всегда будет выглядеть, как рисунок.
Растровая графика. Любую картинку можно разбить на квадраты, получая, таким образом, растр - двумерный массив квадратов. Сами квадраты - элементы растра или пиксели (picture"s element) - элементы картинки. Цвет каждого пикселя кодируется числом, что позволяет для описания картинки задавать порядок номеров цветов (слева направо или сверху вниз). В память записывается номер каждой ячейки, в которой хранится пиксель.
Рисунок в растровом формате
Каждому пикселю сопоставляются значения яркости, цвета, и прозрачности или комбинация этих значений. Растровый образ имеет некоторое число строк и столбцов. Этот способ хранения имеет свои недостатки: больший объём памяти, необходимый для работы с изображениями.
Объем растрового изображения определяется умножением количества пикселей на информационный объем одной точки, который зависит от количества возможных цветов. В современных компьютерах в основном используют следующие разрешающие способности экрана: 640 на 480, 800 на 600, 1024 на 768 и 1280 на 1024 точки. Яркость каждой точки и ее координаты можно выразить с помощью целых чисел, что позволяет использовать двоичный код для того чтобы обрабатывать графические данные.
В простейшем случае (черно-белое изображение без градаций серого цвета) каждая точка экрана может иметь одно из двух состояний - «черная» или «белая», то есть для хранения ее состояния необходим 1 бит. Цветные изображения формируются в соответствии с двоичным кодом цвета каждой точки, хранящимся в видеопамяти. Цветные изображения могут иметь различную глубину цвета, которая задается количеством битов, используемым для кодирования цвета точки. Наиболее распространенными значениями глубины цвета являются 8, 16, 24, 32, 64 бита.
Для кодирования цветных графических изображений произвольный цвет делят на его составляющие. Используются следующие системы кодирования:
HSB (H - оттенок (hue), S - насыщенность (saturation), B - яркость (brightness)),
RGB (Red - красный , Green - зелёный , Blue - синий ) и
CMYK (C yan - голубой, Magenta – пурпурный, Yellow - желтый и Black – черный).
Первая система удобна для человека , вторая - для компьютерной обработки , а последняя - для типографий . Использование этих цветовых систем связано с тем, что световой поток может формироваться излучениями, представляющими собой комбинацию "чистых" спектральных цветов: красного, зеленого, синего или их производных.
Фрактал – это объект, отдельные элементы которого наследуют свойства родительских структур. Поскольку более детальное описание элементов меньшего масштаба происходит по простому алгоритму, описать такой объект можно всего лишь несколькими математическими уравнениями. Фракталы позволяют описывать изображения, для детального представления которых требуется относительно мало памяти.

Рисунок в фрактальном формате
Трёхмерная графика (3 D ) оперирует с объектами в трёхмерном пространстве. Трёхмерная компьютерная графика широко используется в кино, компьютерных играх, где все объекты представляются как набор поверхностей или частиц. Всеми визуальными преобразованиями в 3D-графике управляют с помощью операторов, имеющих матричное представление .
Кодирование звуковой информации
Музыка, как и любой звук, является не чем иным, как звуковыми колебаниями, зарегистрировав которые, её можно достаточно точно воспроизвести. Для представления звукового сигнала в памяти компьютера, необходимо поступившие акустические колебания представить в цифровом виде, то есть преобразовать в последовательность нулей и единиц. С помощью микрофона звук преобразуется в электрические колебания, после чего можно измерить амплитуду колебаний через равные промежутки времени (несколько десятков тысяч раз в секунду), используя специальное устройство - аналого-цифровой преобразователь (АЦП ). Для воспроизведения звука цифровой сигнал необходимо превратить в аналоговый с помощью цифро-аналогового преобразователя (ЦАП ). Оба эти устройства встроены в звуковую карту компьютера. Указанная последовательность превращений представлена на рис. 2.6..

Трансформация аналогового сигнала в цифровой и обратно
Каждое измерение звука записывается в двоичном коде. Этот процесс называется дискретизацией (семплированием), выполняемым с помощью АЦП.
Семпл (sample англ. образец) - это промежуток времени между двумя измерениями амплитуды аналогового сигнала. Кроме промежутка времени семплом называют также любую последовательность цифровых данных, которые получили путем аналого-цифрового преобразования. Важным параметром семплирования является частота - количество измерений амплитуды аналогового сигнала в секунду. Диапазон частоты дискретизации звука от 8000 до 48000 измерений за одну секунду.

Графическое представление процесса дискретизации
На качество воспроизведения влияют частота дискретизации и разрешение (размер ячейки, отведённой под запись значения амплитуды). Например, при записи музыки на компакт-диски используются 16-разрядные значения и частота дискретизации 44032 Гц.
На слух человек воспринимает звуковые волны, имеющие частоту в пределах от 16 Гц до 20 кГц (1 Гц - 1 колебание в секунду).
В формате компакт-дисков Audio DVD за одну секунду сигнал измеряется 96 000 раз, т.е. применяют частоту семплирования 96 кГц. Для экономии места на жестком диске в мультимедийных приложениях довольно часто применяют меньшие частоты: 11, 22, 32 кГц. Это приводит к уменьшению слышимого диапазона частот, а, значит, происходит искажение того, что слышно.



